Reveals critical security vulnerability in LLM-based agents through passive UI tracking, achieving 96% F1 across frontier models—directly relevant to deployed agent trustworthiness.
Addresses fundamental limitation in LoRA fine-tuning by achieving end-to-end isometry in parameter space, advancing parameter-efficient LLM adaptation at scale.
Reframes AI alignment beyond preference aggregation to surface genuine disagreement and pluralism, addressing critical limitation of current RLHF approaches.
Neural networks for fixed-income modeling · No-arbitrage deep learning
Integrates physics-informed constraints (no-arbitrage) into deep generative models for yield curves, resolving ‘manifold collapse’ and achieving consistent term structure forecasting.
Derivatives pricing and volatility · Synthetic data generation
Breaks circular dependency in synthetic option pricing by deriving implied volatility from structural models, enabling synthetic data generation for ML/risk applications.
Introduces dynamic gamma process models for realized volatility in Bayesian framework, improving volatility forecasting through integration of high-frequency data.
Develops deep learning framework for path-dependent convertible bond pricing under complex contractual features, extending DL methods to realistic derivative valuation.
Provides practical guide to IV methods accounting for heterogeneous treatment effects, aligning empirical econometric practice with recent LATE framework advances.
Extends staggered difference-in-differences to settings with network spillovers, enabling policy evaluation under realistic interdependence structures.
Comprehensive guide to deep learning for solving high-dimensional heterogeneous-agent and macro-finance models, addressing curse of dimensionality in economic modeling.
Documents how generative AI reshapes entrepreneurial entry composition (solo vs. teams) using 160K+ product launches, revealing paradox where entry increases but top quality remains team-driven.
An interactive force-directed view of the topic landscape. Drag nodes, zoom, hover for details. Colors come from a Louvain community-detection pass on the co-occurrence graph.
Methodology & cadence
Cadence — runs on the 1st and 15th of each month at 08:00 UTC via GitHub Actions (.github/workflows/ssrn-research.yml). Manual triggers via workflow_dispatch.
Phase A (deterministic) — three arXiv queries, one per bucket, each returning the most-recent 80 candidates filtered to the last 14 days.
Phase B (Claude Haiku tool-use) — picks the top-5 per bucket and clusters all candidates into 5–10 named topics. Edges are not emitted by the model — they’re computed from paper_ids intersections to guarantee consistency.
Snapshots — one JSON per run in ssrn-research/snapshots/. Page reads them all on every render.
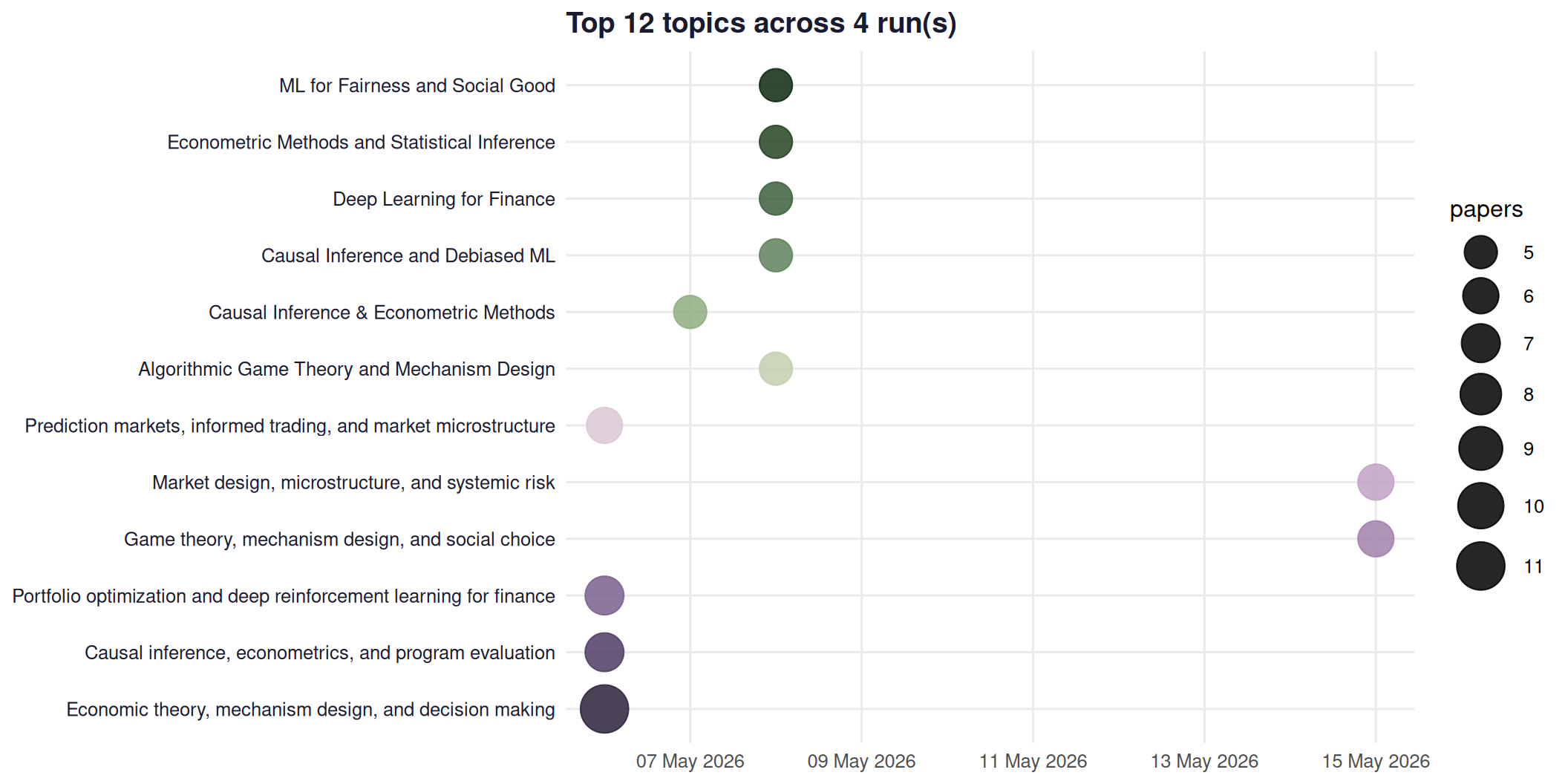
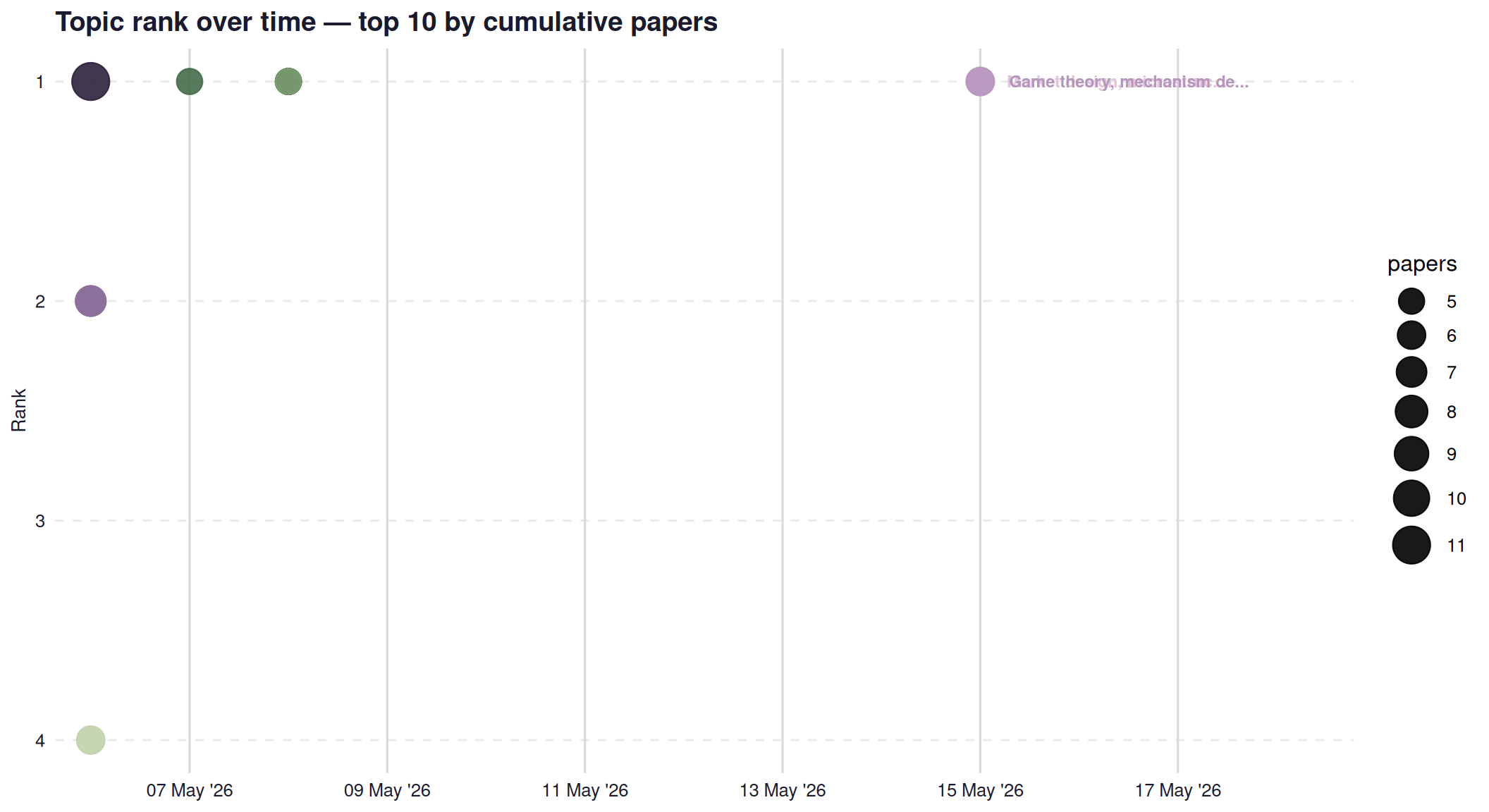
Social Sciences — top 5
#1 — A Practical Guide to Instrumental Variables Methods with Heterogeneous Treatment Effects
Tymon Słoczyński
Causal inference and econometrics
Provides practical guide to IV methods accounting for heterogeneous treatment effects, aligning empirical econometric practice with recent LATE framework advances.
arXiv
#2 — Identification and Estimation of Staggered Difference-in-Differences with Network Spillovers
Hayato Tagawa
Causal inference with spillovers
Extends staggered difference-in-differences to settings with network spillovers, enabling policy evaluation under realistic interdependence structures.
arXiv
#3 — Deep Learning for Solving and Estimating Dynamic Models in Economics and Finance
Simon Scheidegger
Deep learning for dynamic economic models
Comprehensive guide to deep learning for solving high-dimensional heterogeneous-agent and macro-finance models, addressing curse of dimensionality in economic modeling.
arXiv
#4 — Generative AI Fuels Solo Entrepreneurship, but Teams Still Lead at the Top
Hyunso Kim
AI and labor economics · Entrepreneurship
Documents how generative AI reshapes entrepreneurial entry composition (solo vs. teams) using 160K+ product launches, revealing paradox where entry increases but top quality remains team-driven.
arXiv
#5 — Regret Equals Covariance: A Closed-Form Characterization for Stochastic Optimization
Irene Aldridge
Decision theory and optimization
Proves exact closed-form decomposition of regret as covariance between uncertain parameters and optimal decisions, replacing expensive SAA simulation.
arXiv