Oversikt over boligannonser i Oslo, AI-klassifisert i 10 kategorier. Annonsene hentes fra Finn.no annenhver uke, lagres i en SQL-database og behandles her.
Published
May 19, 2026
Utforsk 1 048 boligannonser i Oslo, hentet fra finn.no og klassifisert av AI i 10 boligsegmenter. Bruk diagrammene og kartet nedenfor for å finne mønstre.
1 048 annonser · 1 048 klassifisert · Medianpris 6.4 M NOK · Medianstørrelse 74 m² · Medianpris/m² 95 k NOK · Sist oppdatert 20 Apr 2026
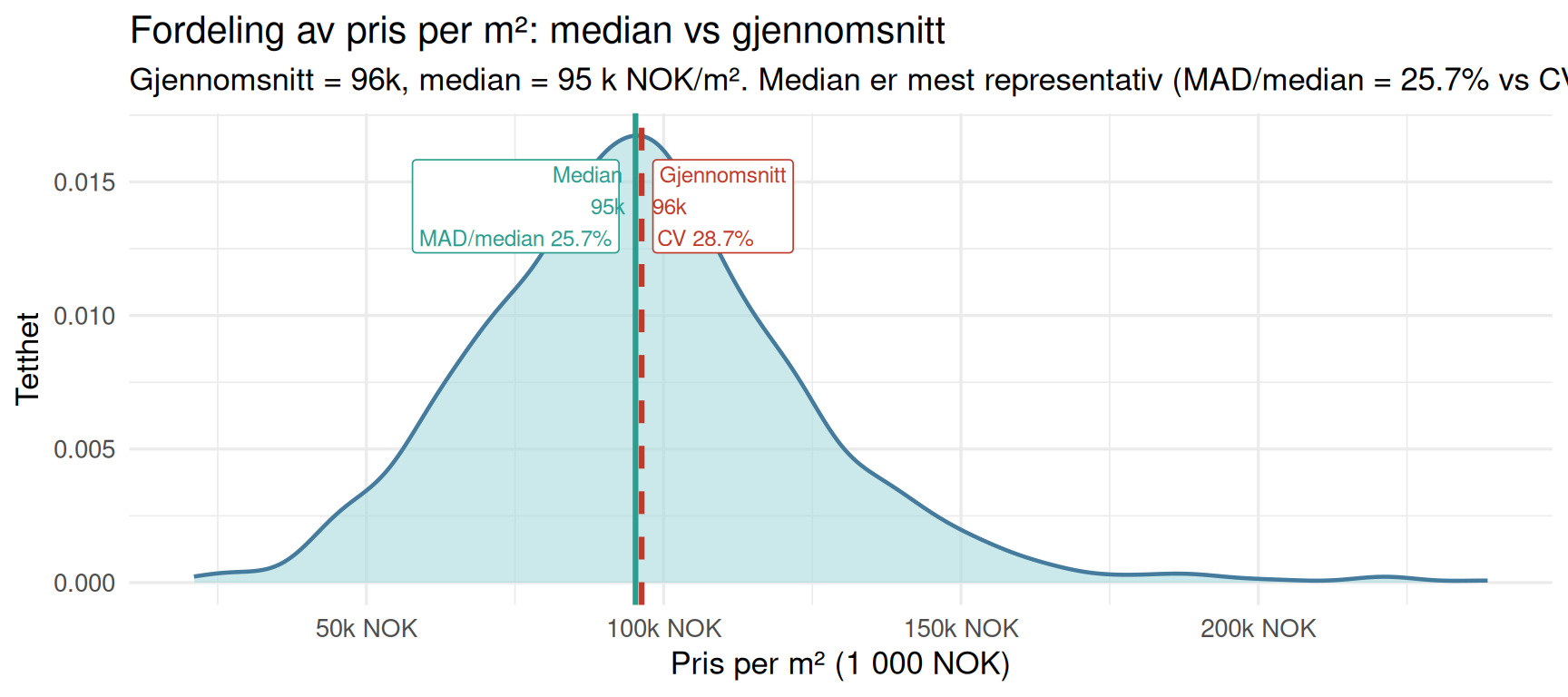
Median vs Gjennomsnitt: Pris per m²
Boligpriser per kvadratmeter er typisk høyreskjevt fordelt — noen få svært dyre boliger drar gjennomsnittet oppover uten å påvirke medianen. Diagrammet under viser fordelingen av pris/m² og sammenligner de to målene, slik at du ser hvilken som er mest representativ for et «typisk» oppgjør.
Oslo på Kartet
Boblestørrelse = prisantydning. Farge = bydel. Klikk en boble for å åpne annonsen.
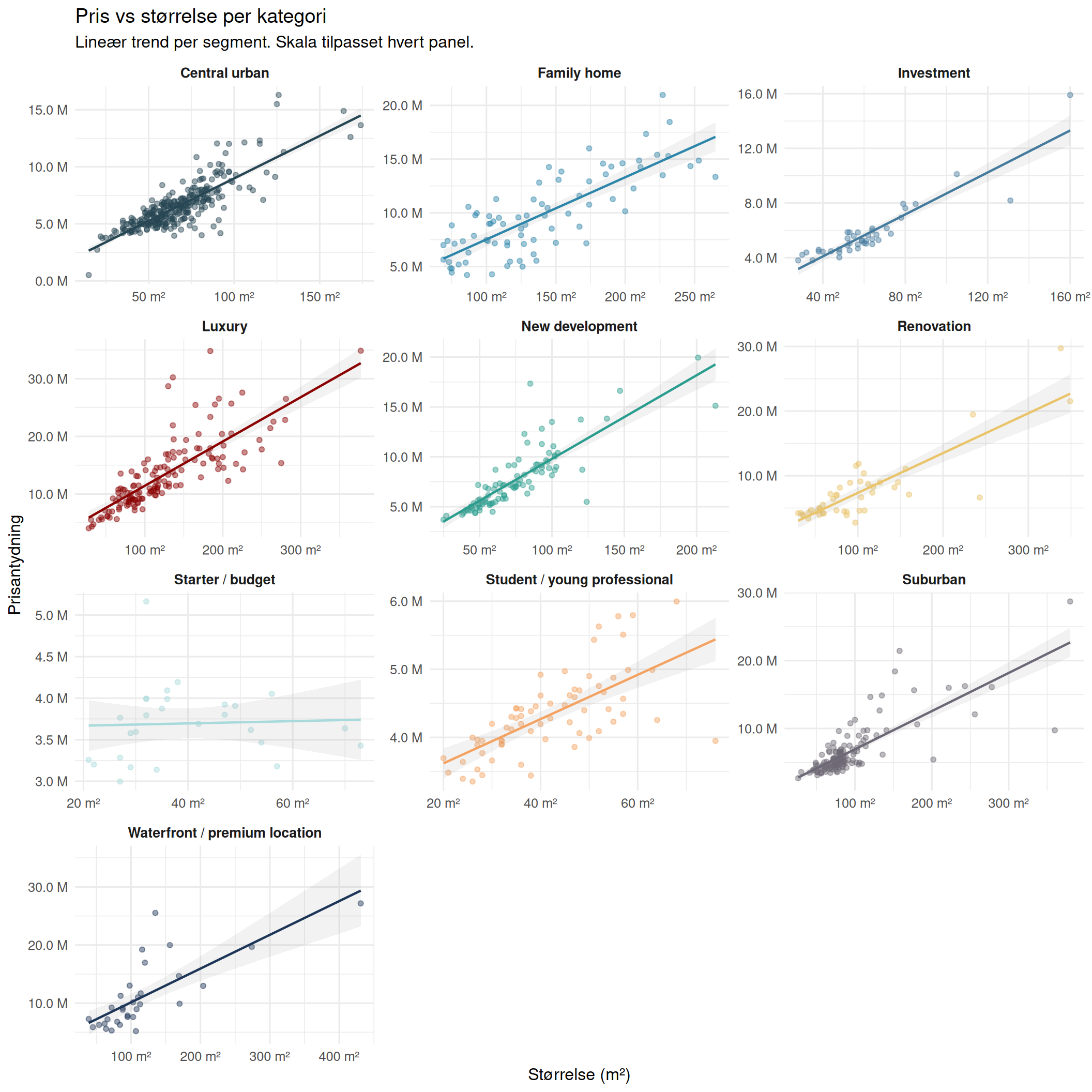
Pris vs Størrelse
Hvert punkt er én annonse. Trendlinjen per panel viser pris–størrelse-sammenhengen innen hvert segment.
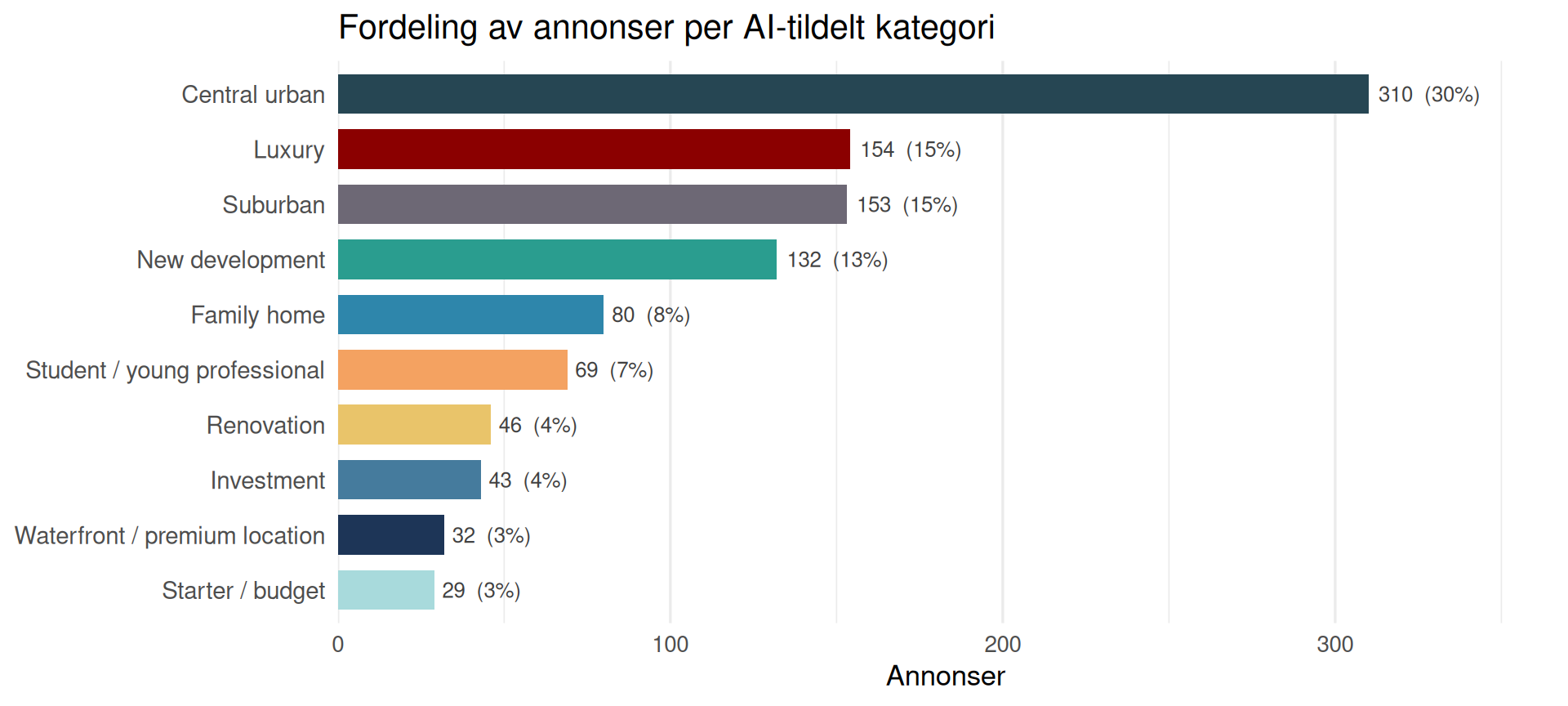
Markedssegmenter
Slik klassifiseres annonsene
Hver annonse klassifiseres automatisk av Claude AI (Haiku) basert på tittel, pris, størrelse, adresse, nabolag, boligtype, byggeår og beskrivelsestekst. Modellen tildeler én av disse 10 kategoriene:
Kategori
Kriterier
Luxury
Eksklusiv eiendom, premium materialer, pris > 8 M NOK, eller prestisjefylt adresse (Frogner, Aker Brygge, Tjuvholmen, Oslofjord)
Family home
3+ rom, egnet for familier, gjerne i utkanten med uteområde eller garasje
Starter / budget
Liten eller rimelig førstegangskjøper-bolig, pris < 3,5 M NOK, 1–2 rom
Investment
Sterkt utleiepotensial, nær universiteter/studentområder (Blindern, Grünerløkka, Sagene, Torshov), eller flerenhetsoppsett
Student / young professional
Liten (1–2 rom), sentral beliggenhet, god kollektivdekning, pris 2–5 M NOK
New development
Bygget 2018 eller senere, eller «nybygg», «prosjekt», «nøkkelferdig» i tittel/beskrivelse
Renovation
Trenger åpenbart arbeid: «oppussingsobjekt», «selges som den er», lav pris/m² (< 40 000 NOK/m²)
Central urban
Mellomklasse byleilighet i sentrale Oslo-bydeler (St. Hanshaugen, Grünerløkka, Majorstuen, Bislett, Sentrum) — ikke luksus
Ved eller nær vann (fjord, elv, innsjø), utsikt, eller premium naturomgivelser
Prioriteringsregler: New development og Renovation går foran plasseringskategorier når bevis er klare. Luxury og Waterfront går foran Central urban og Suburban. Klassifiseringen gjøres i batches og oppdateres ved hver hentekjøring.
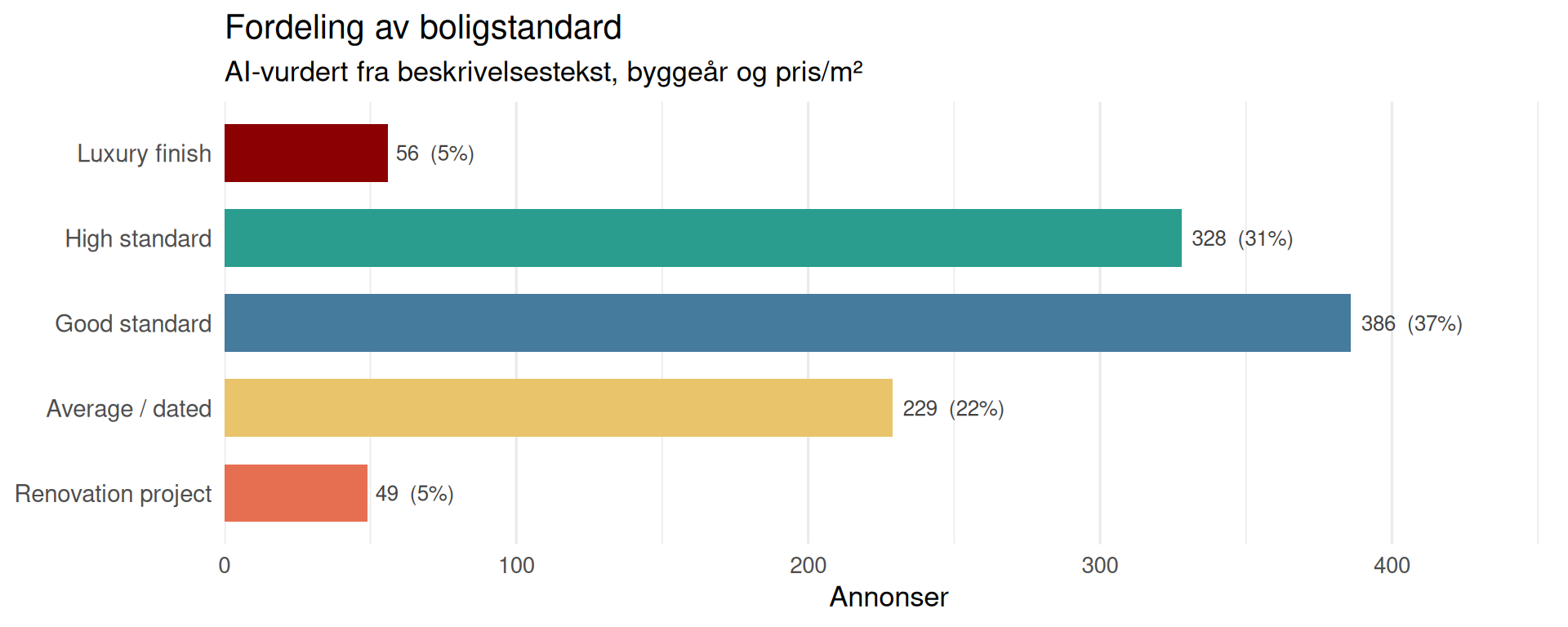
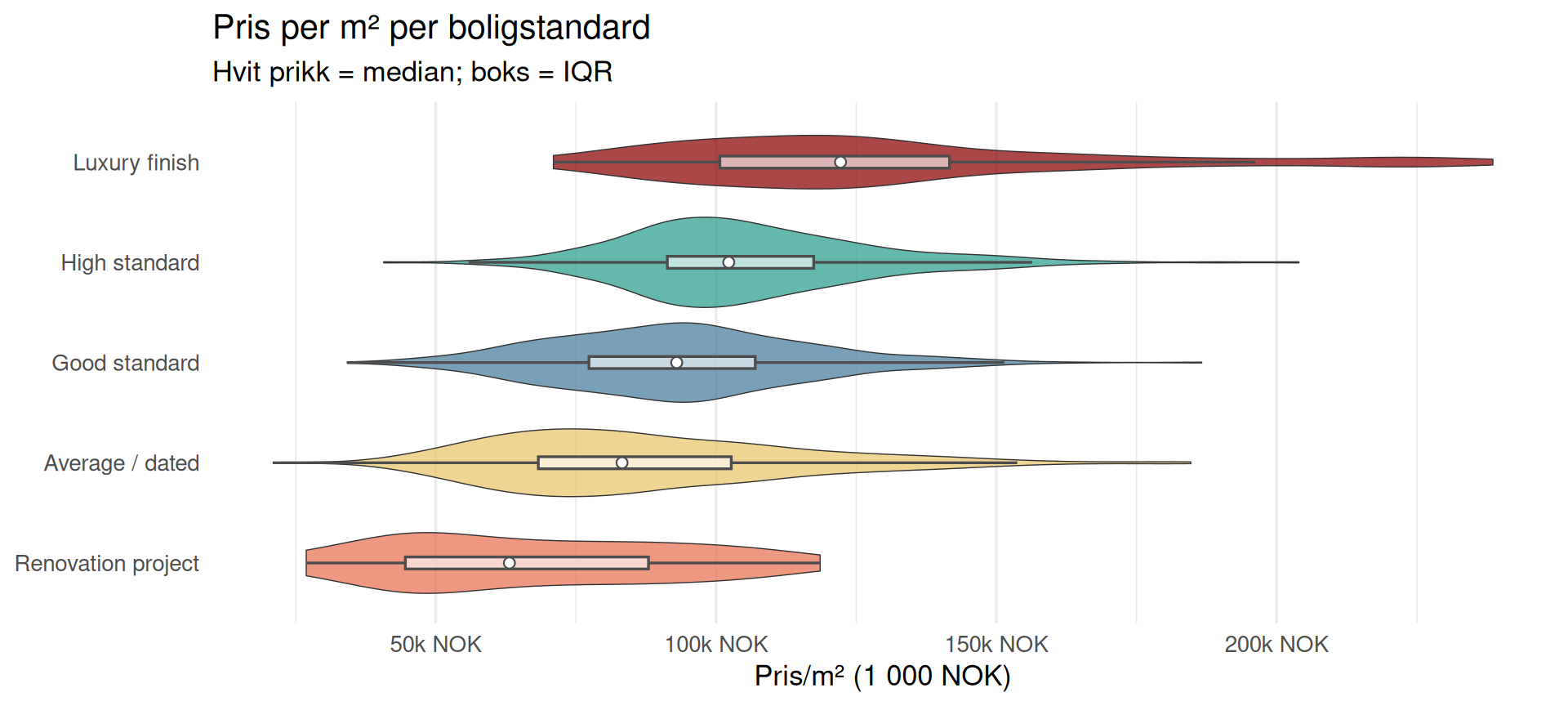
Boligstandard
AI-vurdert innvendig kvalitet og tilstand basert på beskrivelsen (Om boligen), byggeår og pris/m².
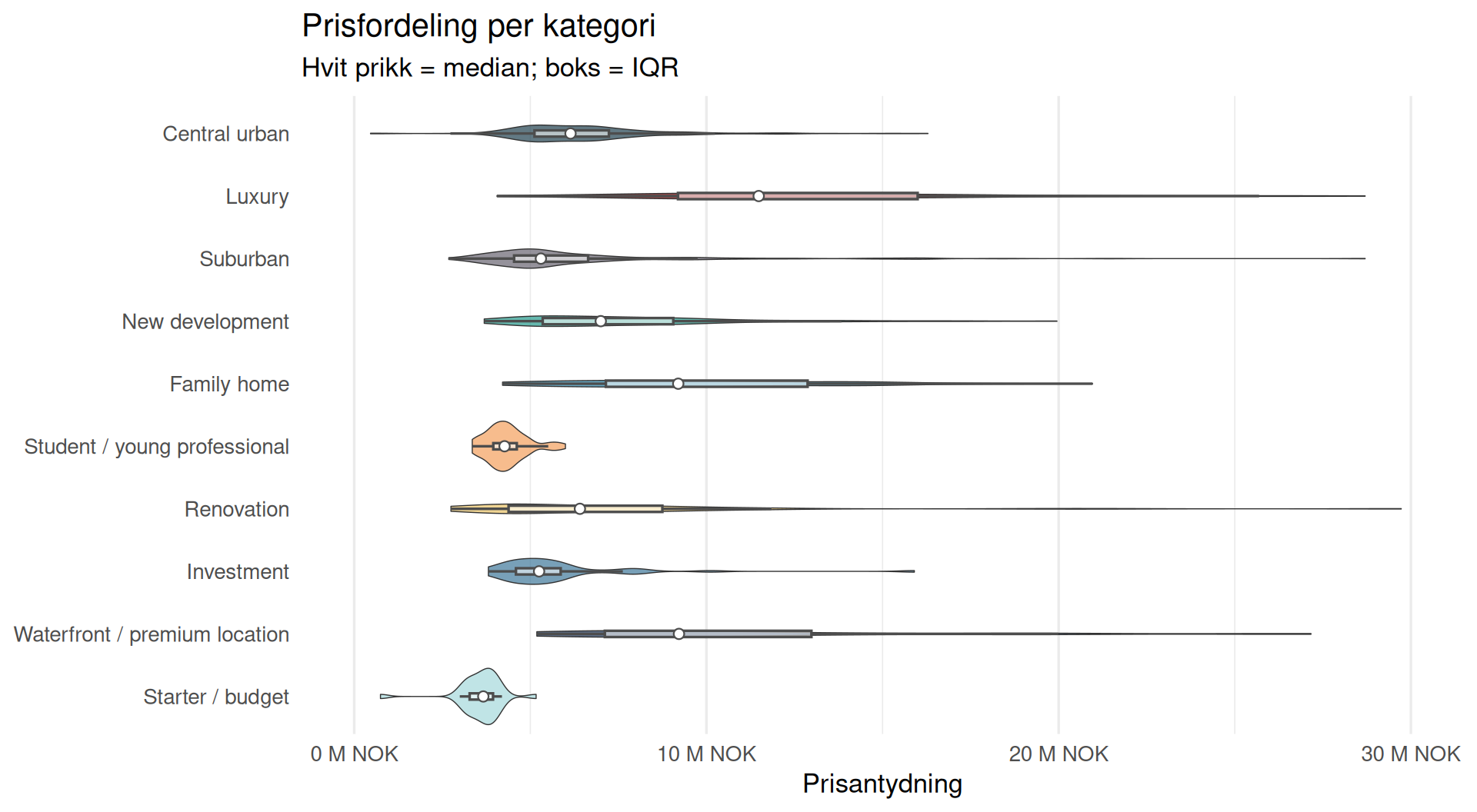
Prisfordeling per Kategori
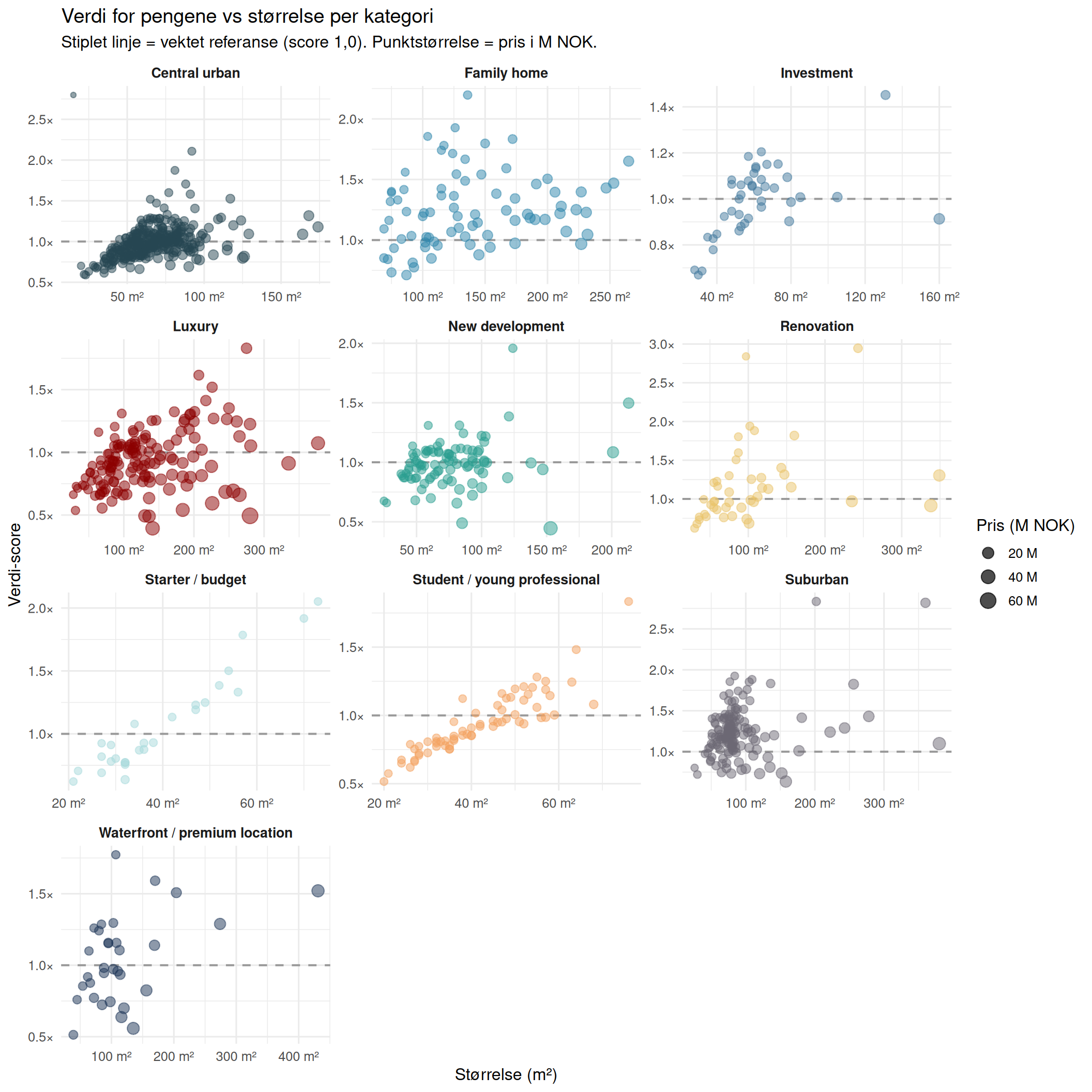
Verdi for Pengene
Hvordan defineres «verdi for pengene» her?
For hver annonse beregner vi en verdi-score basert på et vektet gjennomsnitt av tre referanser:
En score på 1,0 betyr at annonsen er priset nøyaktig på referansen. En score på 1,30 betyr at du betaler 30 % mindre per m² enn referansen — ekte verdi. Scorer under 1,0 indikerer premiumprising. Byens medianpris/m² brukes som fallback der nabolag eller standard mangler data.
Topp 10 Beste Verdi-Annonser
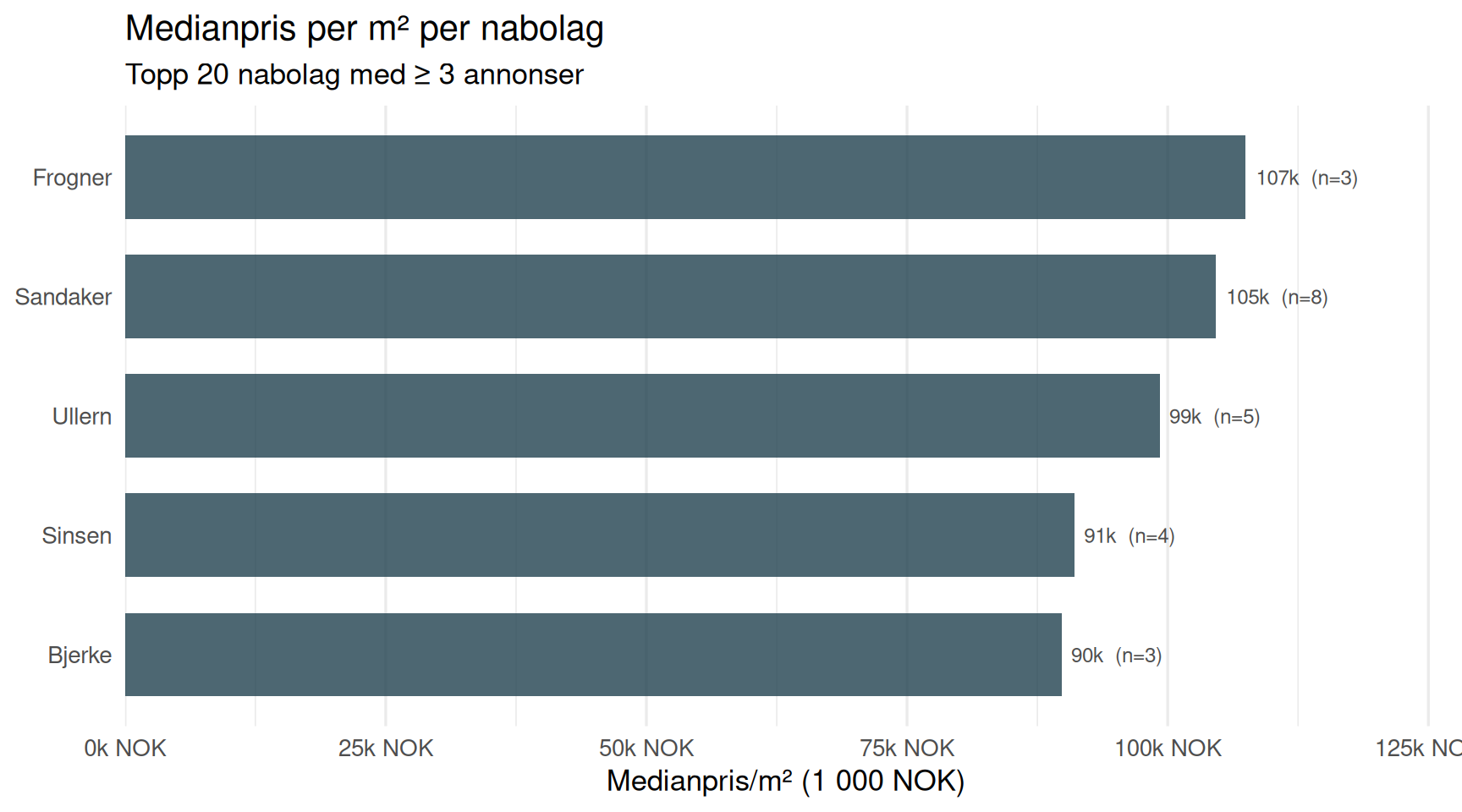
Pris per m² per Nabolag
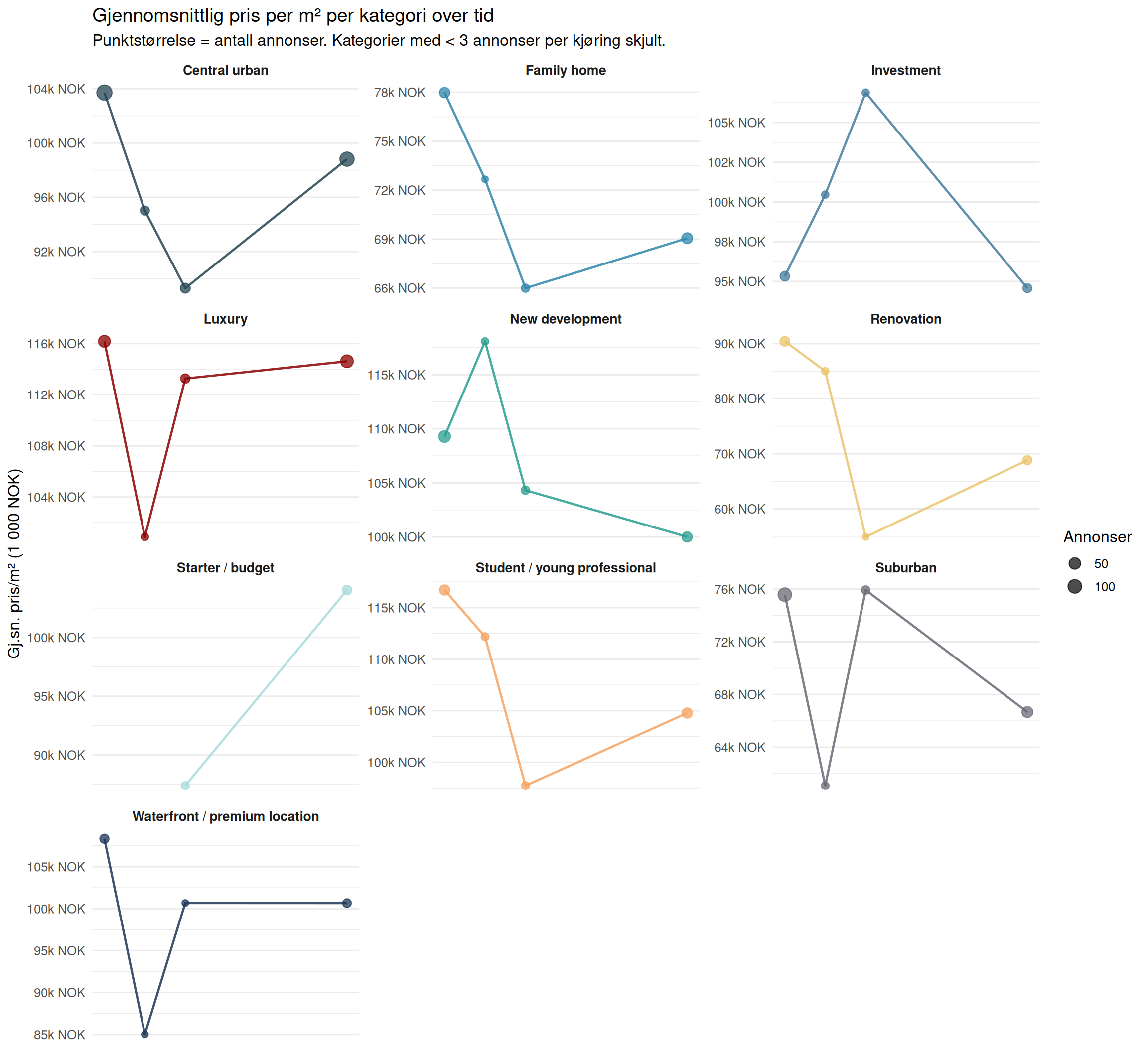
Pris per m² per Kategori Over Tid
Hvordan utvikler gjennomsnittlig prisantydning per m² seg per segment mellom hentekjøringer?
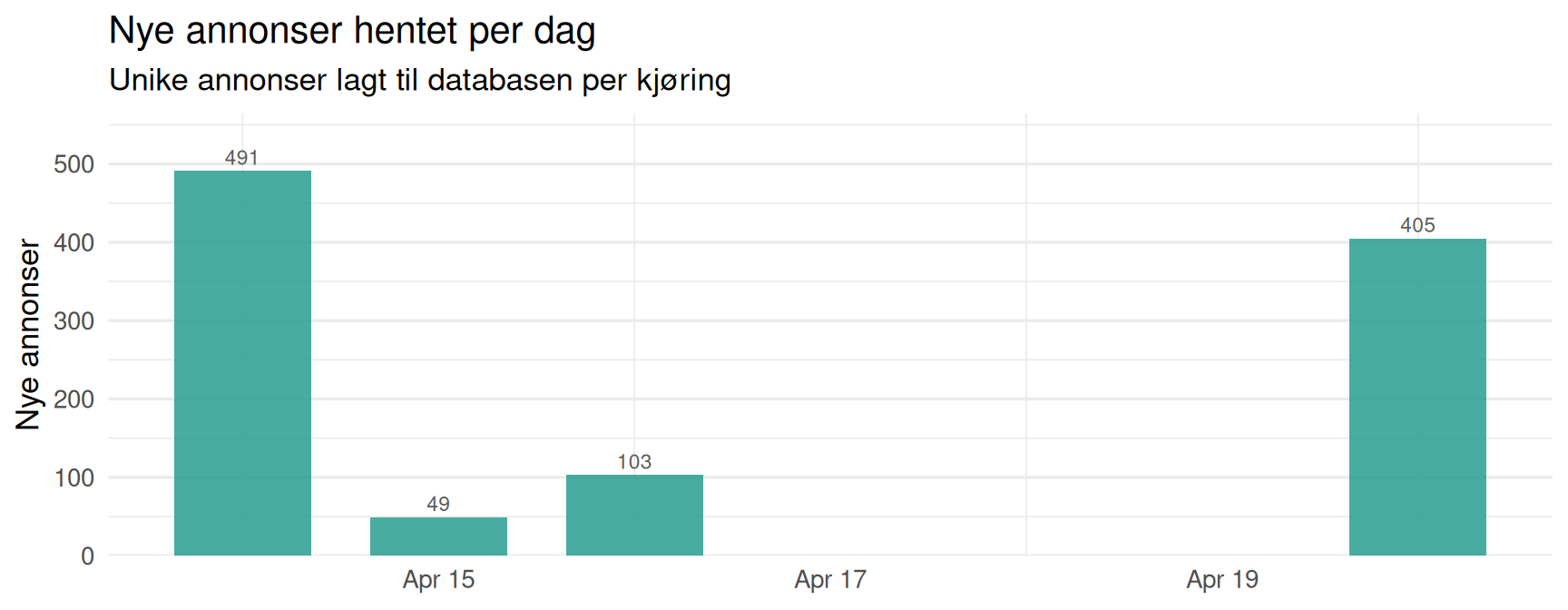
Daglig Annonseaktivitet
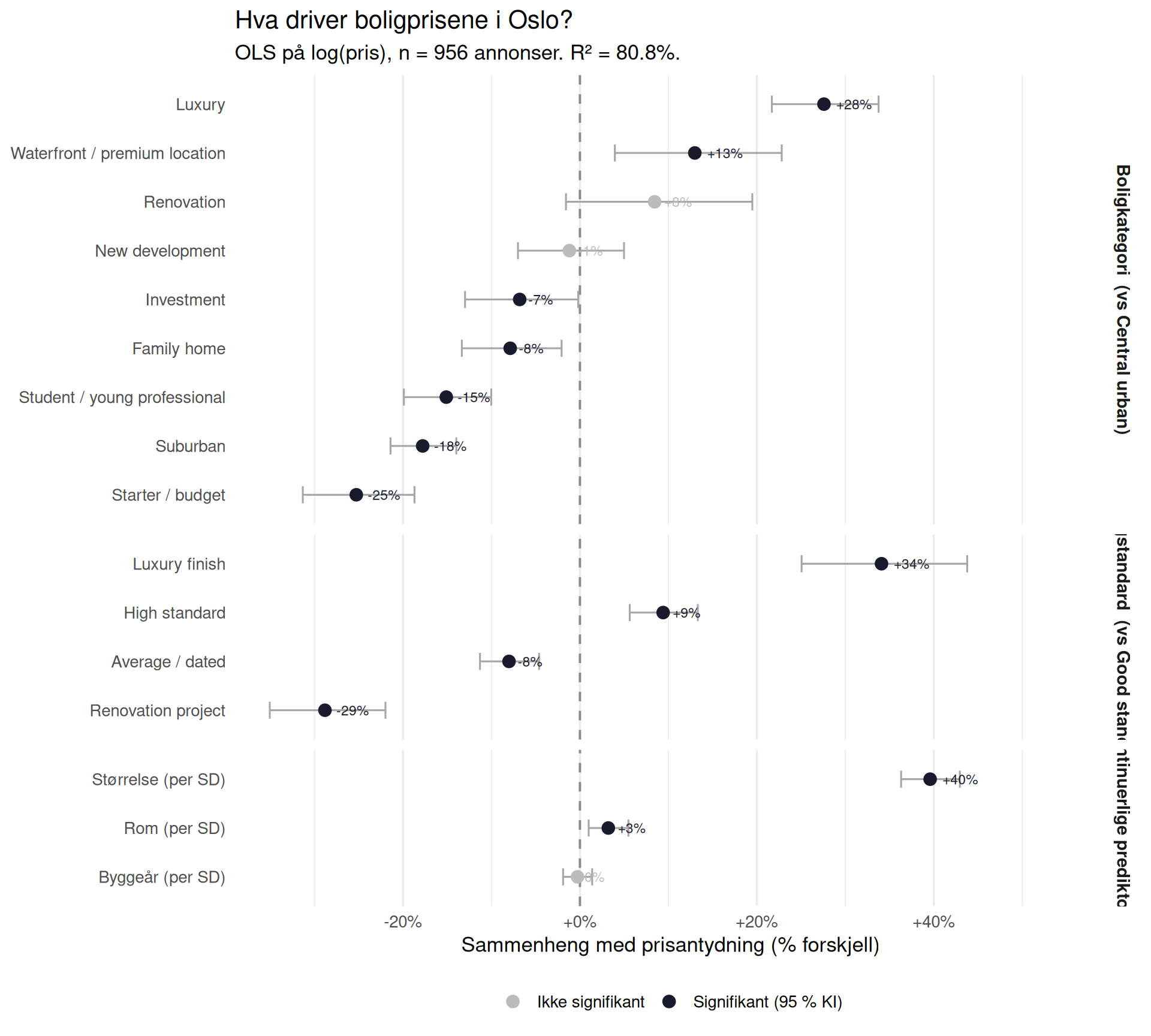
Hva Driver Boligprisene i Oslo?
En OLS-regresjon av log(pris) på alle tilgjengelige prediktorer. Koeffisientene viser % prisforskjell knyttet til hver faktor, med andre holdt konstant. Referansenivåer: Central urban (boligkategori), Good standard (boligstandard). Standard inkluderes når ≥ 30 % av annonsene er klassifisert. Feilstenger = 95 % KI; grått = ikke signifikant.
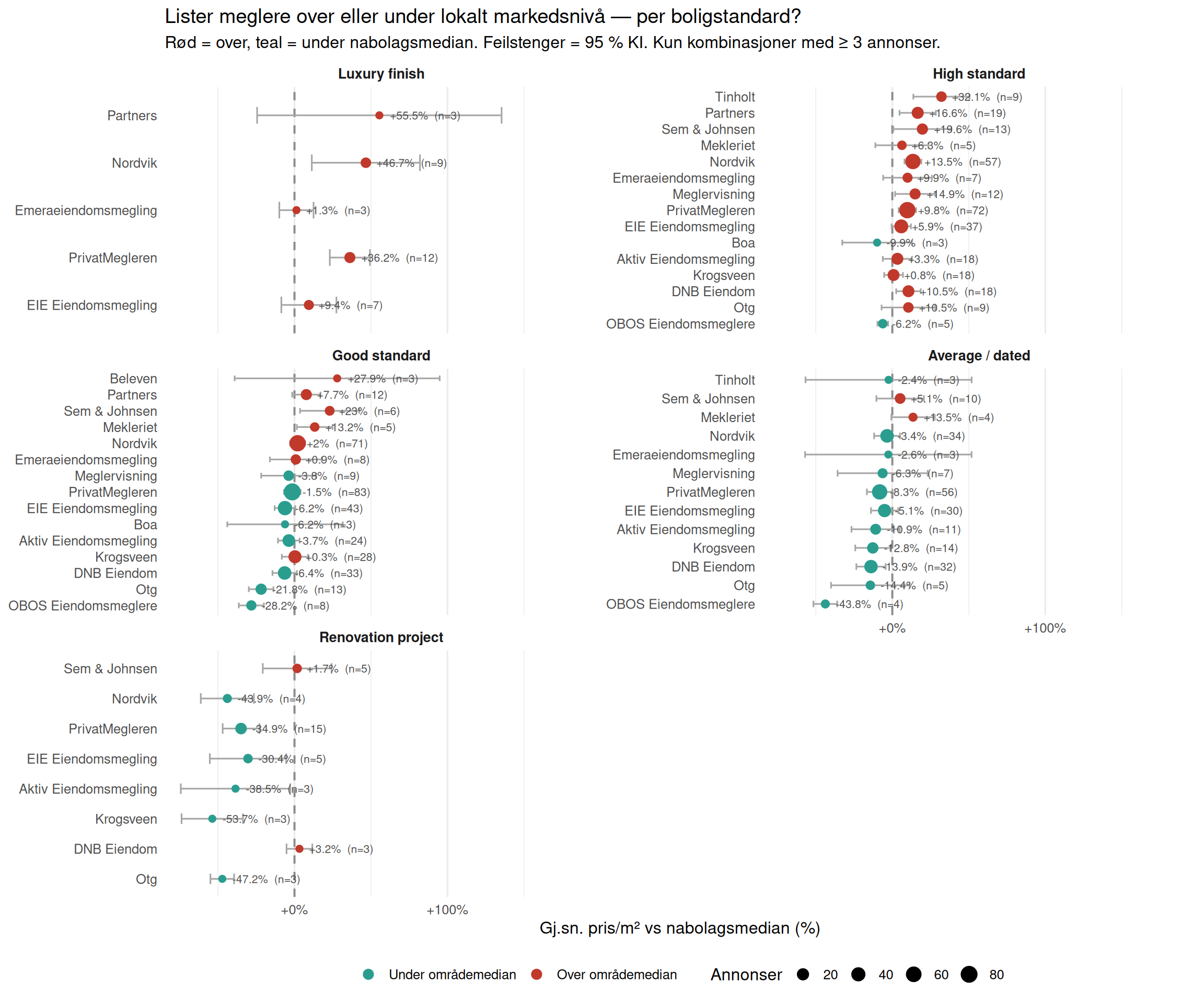
Meglerprising: Over eller Under Lokalt Markedsnivå?
Hvert panel viser én boligstandard. For hvert panel sammenlignes meglernes gjennomsnittlige prisantydning/m² mot nabolagsmedianen (faller tilbake til bymedian der færre enn 3 annonser finnes i et nabolag). Kun megler–standard-kombinasjoner med ≥ 3 annonser vises. Meglere er sortert etter samlet gjennomsnittsavvik på tvers av alle standardnivåer.
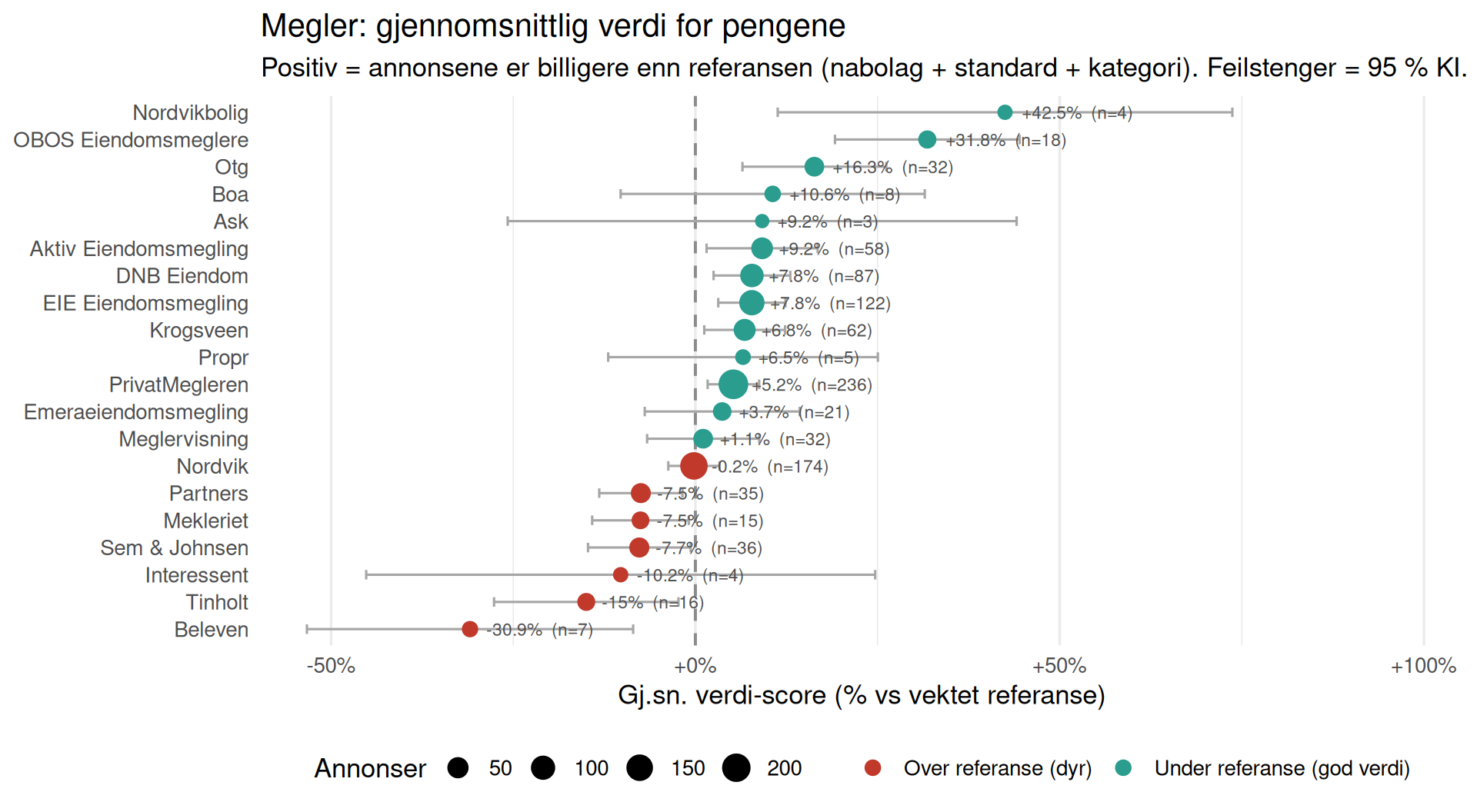
Megler: Verdi for Pengene
Hvilket gjennomsnittlig verdi-score har annonsene til hver megler? Positiv score betyr at meglernes annonser typisk er billigere enn den vektede referansen (nabolag + standard + kategori) — negativ betyr at de typisk er dyrere.
Ukens Bolig
<div class="card border-success mb-4" style="max-width:680px; border-width:2px;">
<div class="card-header bg-success text-white">
<strong>Ukens Bolig</strong>
</div>
<div class="card-body">
<h5 class="card-title mb-1">
<a href="https://www.finn.no/realestate/homes/ad.html?finnkode=405784385" target="_blank" rel="noopener">Bjørndal - Familievennlig enderekkehus over 3 plan | 2 bad | Selveier| Usjenert beliggenhet | Grønne omgivelser</a>
</h5>
<p class="text-muted mb-2" style="font-size:0.9em">Bjørnåsveien 71, Oslo</p>
<div class="d-flex flex-wrap gap-3 mb-3">
<div>
<div class="text-muted" style="font-size:0.75em">PRIS</div>
<strong>5 535 630 NOK</strong>
</div>
<div>
<div class="text-muted" style="font-size:0.75em">STØRRELSE</div>
<strong>136 m²</strong>
</div>
<div>
<div class="text-muted" style="font-size:0.75em">ROM</div>
<strong>5</strong>
</div>
<div>
<div class="text-muted" style="font-size:0.75em">PRIS / m²</div>
<strong>40 703 NOK</strong>
</div>
</div>
<p>
<span class="badge rounded-pill text-white me-2" style="background-color:#2E86AB">Family home</span>
<span class="badge bg-success-subtle text-success-emphasis">+120% vs vektet referanse</span>
</p>
<p class="card-text mb-2" style="font-size:0.88em; border-left:3px solid #198754; padding-left:8px; color:#155724">
<strong>Hvorfor valgt: </strong>
Valgt blant 902 kandidater som beste verdi for pengene i sitt segment. Med 40 703 NOK/m² er den 120 % under den vektede referansen (89 436 NOK/m²). Referansen er gjennomsnittet av nabolagsmedian, standardmedian og kategorimedian for denne boligen.
</p>
<p class="card-text fst-italic text-muted" style="font-size:0.88em; border-left:3px solid #ccc; padding-left:8px">“5-room end-terraced house with 136 m², 2 bathrooms, suburban location (Bjørndal) with green surroundings—ideal family home setup.”</p>
<a href="https://www.finn.no/realestate/homes/ad.html?finnkode=405784385" target="_blank" rel="noopener" class="btn btn-outline-success btn-sm">Se på finn.no →</a>
</div>
<div class="card-footer text-muted" style="font-size:0.8em">Valgt av verdi-score algoritme · Hentet 15 Apr 2026</div>
</div>
Data hentet fra finn.no kun til personlig/utdanningsformål. Kategorier og verdi-scorer beregnet av Claude AI. Dette er ikke finansiell eller investeringsrådgivning.
Source Code
---title: "Oslo Boligmarked"description: "Oversikt over boligannonser i Oslo, AI-klassifisert i 10 kategorier. Annonsene hentes fra Finn.no annenhver uke, lagres i en SQL-database og behandles her."date: todayexecute: freeze: false echo: false warning: false message: false---```{r check-data}# Guard chunk — must be separate from setup so read.csv is never reached when# the file is missing. knitr::opts_chunk$set(eval=FALSE) disables all# subsequent chunks reliably in Quarto (knit_exit() is not reliable here).CSV_PATH <- here::here("finn-housing", "data", "listings_export.csv")if (!file.exists(CSV_PATH)) { cat("> **Ingen data ennå.** Kjør `finn-housing/scraper.R` lokalt (eller vent på den automatiske jobben) for å hente data.\n") knitr::opts_chunk$set(eval = FALSE)}# Ensure ggplot2 figures have a solid white background so they render# correctly when embedded in HTML (theme_minimal uses transparent bg by default)ggplot2::theme_update(plot.background = ggplot2::element_rect(fill = "white", colour = NA))``````{r setup}library(dplyr)library(ggplot2)library(scales)library(forcats)library(leaflet)library(DT)library(stringr)# ── Colour palette (shared across all plots) ──────────────────────────────────CAT_COLORS <- c( "Luxury" = "#8B0000", "Family home" = "#2E86AB", "Starter / budget" = "#A8DADC", "Investment" = "#457B9D", "Student / young professional" = "#F4A261", "New development" = "#2A9D8F", "Renovation" = "#E9C46A", "Central urban" = "#264653", "Suburban" = "#6D6875", "Waterfront / premium location" = "#1D3557", "Unclassified" = "#BBBBBB")# ── Load & clean data ─────────────────────────────────────────────────────────raw <- read.csv(CSV_PATH, stringsAsFactors = FALSE, fileEncoding = "UTF-8")raw <- raw |> # Add optional columns that may be absent from older CSV exports (\(d) { for (col in c("broker", "standard", "standard_confidence", "standard_reasoning")) { if (!col %in% names(d)) d[[col]] <- NA_character_ } for (col in c("floor", "has_balcony")) { if (!col %in% names(d)) d[[col]] <- NA_integer_ } d })()df <- raw |> mutate( # Cast all optional text columns to character — prevents logical-NA vs character # type conflicts in coalesce() when columns are entirely NA in the CSV across(any_of(c("title", "address", "neighborhood", "property_type", "broker", "category", "category_confidence", "category_reasoning", "classified_at", "standard", "standard_confidence", "standard_reasoning", "url")), as.character), scraped_date = as.Date(substr(scraped_at, 1, 10)), price_m = price / 1e6, price_sqm = ifelse(!is.na(price) & !is.na(size_sqm) & size_sqm > 0, price / size_sqm, NA_real_), category = ifelse(is.na(category) | category == "", "Unclassified", category), lat = suppressWarnings(as.numeric(lat)), lon = suppressWarnings(as.numeric(lon)) )classified <- df |> filter(category != "Unclassified")# ── Value-for-money score (vektet: nabolag + standard + kategori) ─────────────# ref_psqm = (neighbourhood_median + standard_median + category_median) / 3# score = ref_psqm / listing_price_sqm# score > 1 → cheaper than the weighted reference → good value# score < 1 → more expensive than the weighted reference → premium pricing## City-wide median is used as fallback for any component where data is thin.city_med_psqm <- median( classified$price_sqm[classified$price_sqm > 10000 & classified$price_sqm < 250000], na.rm = TRUE)hood_med_lookup <- classified |> filter(!is.na(neighborhood), neighborhood != "", !is.na(price_sqm), price_sqm > 10000, price_sqm < 250000) |> group_by(neighborhood) |> summarise(hood_med_psqm = median(price_sqm, na.rm = TRUE), n_hood = n(), .groups = "drop") |> filter(n_hood >= 3)cat_med_lookup <- classified |> filter(!is.na(price_sqm), price_sqm > 10000, price_sqm < 250000) |> group_by(category) |> summarise(cat_med_psqm = median(price_sqm, na.rm = TRUE), .groups = "drop")std_med_lookup <- classified |> filter(!is.na(standard), standard != "", !is.na(price_sqm), price_sqm > 10000, price_sqm < 250000) |> group_by(standard) |> summarise(std_med_psqm = median(price_sqm, na.rm = TRUE), .groups = "drop")classified <- classified |> left_join(hood_med_lookup, by = "neighborhood") |> left_join(cat_med_lookup, by = "category") |> left_join(std_med_lookup, by = "standard") |> mutate( hood_ref = if_else(!is.na(hood_med_psqm), hood_med_psqm, city_med_psqm), cat_ref = if_else(!is.na(cat_med_psqm), cat_med_psqm, city_med_psqm), std_ref = if_else(!is.na(std_med_psqm), std_med_psqm, city_med_psqm), ref_psqm = (hood_ref + cat_ref + std_ref) / 3, value_score = if_else(!is.na(price_sqm) & price_sqm > 0, ref_psqm / price_sqm, NA_real_), value_pct = round((value_score - 1) * 100, 1) )last_scrape <- max(df$scraped_date, na.rm = TRUE)total_n <- nrow(df)classified_n <- nrow(classified)med_price <- median(classified$price, na.rm = TRUE)med_size <- median(classified$size_sqm, na.rm = TRUE)med_psqm <- median(classified$price_sqm, na.rm = TRUE)```Utforsk **`r format(total_n, big.mark = " ")`** boligannonser i Oslo, hentet fra finn.no og klassifisert av AI i 10 boligsegmenter. Bruk diagrammene og kartet nedenfor for å finne mønstre.---::: {.callout-note appearance="minimal"}**`r format(total_n, big.mark = " ")`** annonser · **`r format(classified_n, big.mark = " ")`** klassifisert · Medianpris **`r paste0(round(med_price / 1e6, 1), " M NOK")`** · Medianstørrelse **`r paste0(round(med_size), " m²")`** · Medianpris/m² **`r paste0(format(round(med_psqm / 1000, 0), big.mark = " "), " k NOK")`** · Sist oppdatert **`r format(last_scrape, "%d %b %Y")`**:::---## Median vs Gjennomsnitt: Pris per m²::: {.callout-note appearance="minimal"}Boligpriser per kvadratmeter er typisk høyreskjevt fordelt — noen få svært dyre boliger drar **gjennomsnittet** oppover uten å påvirke **medianen**. Diagrammet under viser fordelingen av pris/m² og sammenligner de to målene, slik at du ser hvilken som er mest representativ for et «typisk» oppgjør.:::```{r psqm-density, fig.height=4, fig.width=9}dens_df <- classified |> filter(!is.na(price_sqm), price_sqm > 10000, price_sqm < 250000)med_val <- median(dens_df$price_sqm)mean_val <- mean(dens_df$price_sqm)cv_mean <- round(sd(dens_df$price_sqm) / mean_val * 100, 1)cv_med <- round(mad(dens_df$price_sqm) / med_val * 100, 1)better_txt <- if (cv_med < cv_mean) { paste0("Median er mest representativ (MAD/median = ", cv_med, "% vs CV = ", cv_mean, "%).")} else { paste0("Gjennomsnitt er mest stabilt her (CV = ", cv_mean, "% vs MAD/median = ", cv_med, "%).")}subtitle_txt <- paste0( "Gjennomsnitt = ", round(mean_val / 1000, 0), "k, median = ", round(med_val / 1000, 0), " k NOK/m². ", better_txt)# Label positions: median label left-of-line, mean label right-of-linemed_hjust <- if (mean_val > med_val) 1.08 else -0.08mean_hjust <- if (mean_val > med_val) -0.08 else 1.08ggplot(dens_df, aes(x = price_sqm / 1000)) + geom_density(fill = "#A8DADC", colour = "#457B9D", alpha = 0.6, linewidth = 0.8) + geom_vline(xintercept = med_val / 1000, colour = "#2A9D8F", linewidth = 1.1) + geom_vline(xintercept = mean_val / 1000, colour = "#C0392B", linewidth = 1.1, linetype = "dashed") + annotate("label", x = med_val / 1000, y = Inf, vjust = 1.5, hjust = med_hjust, label = paste0("Median\n", round(med_val / 1000, 0), "k\nMAD/median ", cv_med, "%"), colour = "#2A9D8F", fill = "white", size = 3.2, label.size = 0.3) + annotate("label", x = mean_val / 1000, y = Inf, vjust = 1.5, hjust = mean_hjust, label = paste0("Gjennomsnitt\n", round(mean_val / 1000, 0), "k\nCV ", cv_mean, "%"), colour = "#C0392B", fill = "white", size = 3.2, label.size = 0.3) + scale_x_continuous(labels = label_number(suffix = "k NOK", accuracy = 1)) + labs(x = "Pris per m² (1 000 NOK)", y = "Tetthet", title = "Fordeling av pris per m²: median vs gjennomsnitt", subtitle = subtitle_txt) + theme_minimal(base_size = 13)```---## Oslo på Kartet*Boblestørrelse = prisantydning. Farge = bydel. Klikk en boble for å åpne annonsen.*```{r map}# Neighbourhood string → official Oslo bydelBYDEL_LOOKUP <- c( "Frogner" = "Frogner", "Grünerløkka" = "Grünerløkka", "Sagene" = "Sagene", "Gamle Oslo" = "Gamle Oslo", "St. Hanshaugen" = "St. Hanshaugen", "Nordstrand" = "Nordstrand", "Østensjø" = "Østensjø", "Alna" = "Alna", "Bjerke" = "Bjerke", "Grorud" = "Grorud", "Stovner" = "Stovner", "Søndre Nordstrand" = "Søndre Nordstrand", "Ullern" = "Ullern", "Vestre Aker" = "Vestre Aker", "Nordre Aker" = "Nordre Aker", "Sentrum" = "Sentrum", "Majorstuen" = "Frogner", "Vålerenga" = "Gamle Oslo", "Tøyen" = "Gamle Oslo", "Grønland" = "Gamle Oslo", "Kampen" = "Gamle Oslo", "Torshov" = "Sagene", "Iladalen" = "Sagene", "Sandaker" = "Sagene", "Bislett" = "St. Hanshaugen", "Adamstuen" = "St. Hanshaugen", "Sinsen" = "Nordre Aker", "Grefsen" = "Nordre Aker", "Storo" = "Nordre Aker", "Nydalen" = "Nordre Aker", "Kjelsås" = "Nordre Aker", "Nordberg" = "Nordre Aker", "Skøyen" = "Ullern", "Bestum" = "Ullern", "Røa" = "Vestre Aker", "Vinderen" = "Vestre Aker", "Slemdal" = "Vestre Aker", "Smestad" = "Vestre Aker", "Hovseter" = "Vestre Aker", "Holmlia" = "Søndre Nordstrand", "Mortensrud" = "Søndre Nordstrand", "Bjørndal" = "Søndre Nordstrand", "Lambertseter" = "Østensjø", "Bøler" = "Østensjø", "Manglerud" = "Østensjø", "Godlia" = "Østensjø", "Oppsal" = "Østensjø", "Romsås" = "Grorud", "Ammerud" = "Grorud", "Rødtvet" = "Grorud", "Furuset" = "Alna", "Helsfyr" = "Alna", "Teisen" = "Alna", "Hellerud" = "Alna", "Bekkelaget" = "Nordstrand", "Ljan" = "Nordstrand", "Ekeberg" = "Nordstrand")map_df <- df |> filter(!is.na(lat), !is.na(lon), lat > 59.5, lat < 60.2, lon > 10.3, lon < 11.2, !is.na(price))if (nrow(map_df) == 0) { cat("> Kartet vises når geokoding har kjørt (skjer automatisk etter hvert klassifiseringssteg).\n")} else { map_df <- map_df |> mutate( bydel = { b <- BYDEL_LOOKUP[coalesce(neighborhood, "")] ifelse(is.na(b), "Ukjent", unname(b)) }, radius = pmin(pmax(log(price / 1e6) * 5, 4), 22), cat_hex = coalesce(CAT_COLORS[category], "#BBBBBB"), popup_txt = paste0( "<b><a href='", url, "' target='_blank'>", title, "</a></b><br>", "<b>", ifelse(!is.na(price), paste0(format(price, big.mark = " "), " NOK"), "—"), "</b>", ifelse(!is.na(size_sqm), paste0(" · ", size_sqm, " m²"), ""), ifelse(!is.na(rooms), paste0(" · ", rooms, " rom"), ""), "<br>", ifelse(!is.na(address), paste0(address, "<br>"), ""), ifelse(!is.na(neighborhood) & neighborhood != "", paste0("<i>", neighborhood, " (", bydel, ")</i><br>"), ""), "<span style='background:", cat_hex, ";color:#fff;padding:2px 6px;border-radius:3px;font-size:0.8em'>", category, "</span>" ) ) # Colour palette keyed on bydeler present in the data present_bydeler <- sort(unique(map_df$bydel)) n_bd <- length(present_bydeler) bd_raw <- if (n_bd <= 12) { MetBrewer::met.brewer("Cassatt2", max(n_bd, 2L)) } else { colorRampPalette(MetBrewer::met.brewer("Cassatt2", 12L))(n_bd) } BYDEL_COLORS <- setNames(as.character(bd_raw), present_bydeler) BYDEL_COLORS["Ukjent"] <- "#BBBBBB" map_df <- map_df |> mutate(col_hex = coalesce(BYDEL_COLORS[bydel], "#BBBBBB")) leg_bydeler <- present_bydeler[present_bydeler != "Ukjent"] if (any(map_df$bydel == "Ukjent")) leg_bydeler <- c(leg_bydeler, "Ukjent") leaflet(map_df) |> addProviderTiles(providers$CartoDB.Positron) |> setView(lng = 10.757, lat = 59.913, zoom = 11) |> addCircleMarkers( lng = ~lon, lat = ~lat, radius = ~radius, color = ~col_hex, fillColor = ~col_hex, fillOpacity = 0.65, weight = 1, opacity = 0.9, popup = ~popup_txt ) |> addLegend( position = "bottomright", colors = BYDEL_COLORS[leg_bydeler], labels = leg_bydeler, title = "Bydel", opacity = 0.8 )}```---## Pris vs Størrelse*Hvert punkt er én annonse. Trendlinjen per panel viser pris–størrelse-sammenhengen innen hvert segment.*```{r price-size, fig.height=11, fig.width=11}scatter_df <- classified |> filter(!is.na(price_m), !is.na(size_sqm), price_m > 0.3, price_m < 35, size_sqm > 10, size_sqm < 450)ggplot(scatter_df, aes(x = size_sqm, y = price_m, colour = category)) + geom_point(alpha = 0.45, size = 1.4) + geom_smooth(method = "lm", formula = y ~ x, linewidth = 0.8, se = TRUE, alpha = 0.12) + scale_colour_manual(values = CAT_COLORS, guide = "none") + scale_y_continuous(labels = label_number(suffix = " M", accuracy = 0.5)) + scale_x_continuous(labels = label_number(suffix = " m²")) + facet_wrap(~category, scales = "free", ncol = 3) + labs(x = "Størrelse (m²)", y = "Prisantydning", title = "Pris vs størrelse per kategori", subtitle = "Lineær trend per segment. Skala tilpasset hvert panel.") + theme_minimal(base_size = 12) + theme(strip.text = element_text(face = "bold", size = 10))```---## Markedssegmenter```{r segments, fig.height=4.5, fig.width=10}cat_counts <- classified |> count(category, name = "n") |> arrange(desc(n)) |> mutate( category = factor(category, levels = category), pct = n / sum(n) * 100, label = paste0(n, " (", round(pct), "%)") )ggplot(cat_counts, aes(x = n, y = fct_rev(category), fill = category)) + geom_col(show.legend = FALSE, width = 0.72) + geom_text(aes(label = label), hjust = -0.1, size = 3.4, colour = "grey25") + scale_fill_manual(values = CAT_COLORS) + scale_x_continuous(expand = expansion(mult = c(0, 0.18))) + labs(x = "Annonser", y = NULL, title = "Fordeling av annonser per AI-tildelt kategori") + theme_minimal(base_size = 13) + theme(panel.grid.major.y = element_blank(), axis.text.y = element_text(size = 11))```::: {.callout-note appearance="minimal" collapse="true"}#### Slik klassifiseres annonseneHver annonse klassifiseres automatisk av Claude AI (Haiku) basert på tittel, pris, størrelse, adresse, nabolag, boligtype, byggeår og beskrivelsestekst. Modellen tildeler én av disse 10 kategoriene:| Kategori | Kriterier ||---|---|| **Luxury** | Eksklusiv eiendom, premium materialer, pris > 8 M NOK, eller prestisjefylt adresse (Frogner, Aker Brygge, Tjuvholmen, Oslofjord) || **Family home** | 3+ rom, egnet for familier, gjerne i utkanten med uteområde eller garasje || **Starter / budget** | Liten eller rimelig førstegangskjøper-bolig, pris < 3,5 M NOK, 1–2 rom || **Investment** | Sterkt utleiepotensial, nær universiteter/studentområder (Blindern, Grünerløkka, Sagene, Torshov), eller flerenhetsoppsett || **Student / young professional** | Liten (1–2 rom), sentral beliggenhet, god kollektivdekning, pris 2–5 M NOK || **New development** | Bygget 2018 eller senere, eller «nybygg», «prosjekt», «nøkkelferdig» i tittel/beskrivelse || **Renovation** | Trenger åpenbart arbeid: «oppussingsobjekt», «selges som den er», lav pris/m² (< 40 000 NOK/m²) || **Central urban** | Mellomklasse byleilighet i sentrale Oslo-bydeler (St. Hanshaugen, Grünerløkka, Majorstuen, Bislett, Sentrum) — ikke luksus || **Suburban** | I ytre Oslo-bydeler (Nordstrand, Østensjø, Røa, Holmlia, Bøler, Groruddalen, Ullern, Vestre Aker) || **Waterfront / premium location** | Ved eller nær vann (fjord, elv, innsjø), utsikt, eller premium naturomgivelser |Prioriteringsregler: *New development* og *Renovation* går foran plasseringskategorier når bevis er klare. *Luxury* og *Waterfront* går foran *Central urban* og *Suburban*. Klassifiseringen gjøres i batches og oppdateres ved hver hentekjøring.:::---## Boligstandard*AI-vurdert innvendig kvalitet og tilstand basert på beskrivelsen (Om boligen), byggeår og pris/m².*```{r standard-chart, fig.height=4, fig.width=10}STANDARD_COLORS <- c( "Luxury finish" = "#8B0000", "High standard" = "#2A9D8F", "Good standard" = "#457B9D", "Average / dated" = "#E9C46A", "Renovation project" = "#E76F51")STANDARD_ORDER <- c("Luxury finish", "High standard", "Good standard", "Average / dated", "Renovation project")std_df <- df |> filter(!is.na(standard), standard != "") |> mutate(standard = factor(standard, levels = STANDARD_ORDER))if (nrow(std_df) < 3) { cat("> Standardklassifisering vises etter at classify.R har kjørt.\n")} else { std_counts <- std_df |> count(standard, name = "n") |> mutate( pct = n / sum(n) * 100, label = paste0(n, " (", round(pct), "%)") ) ggplot(std_counts, aes(x = n, y = fct_rev(standard), fill = standard)) + geom_col(show.legend = FALSE, width = 0.68) + geom_text(aes(label = label), hjust = -0.1, size = 3.4, colour = "grey25") + scale_fill_manual(values = STANDARD_COLORS) + scale_x_continuous(expand = expansion(mult = c(0, 0.18))) + labs(x = "Annonser", y = NULL, title = "Fordeling av boligstandard", subtitle = "AI-vurdert fra beskrivelsestekst, byggeår og pris/m²") + theme_minimal(base_size = 13) + theme(panel.grid.major.y = element_blank(), axis.text.y = element_text(size = 11))}``````{r standard-price, fig.height=4.5, fig.width=10}std_price_df <- df |> filter(!is.na(standard), standard != "", !is.na(price_sqm), price_sqm > 10000, price_sqm < 250000) |> mutate(standard = factor(standard, levels = STANDARD_ORDER))enough_std <- std_price_df |> count(standard) |> filter(n >= 3) |> pull(standard)if (length(enough_std) < 2) { cat("> Pris per standard vises med mer data.\n")} else { ggplot(std_price_df |> filter(standard %in% enough_std), aes(x = price_sqm / 1000, y = fct_rev(standard), fill = standard)) + geom_violin(trim = TRUE, show.legend = FALSE, alpha = 0.72, linewidth = 0.25) + geom_boxplot(width = 0.12, outlier.shape = NA, show.legend = FALSE, colour = "grey30", fill = "white", alpha = 0.6) + stat_summary(fun = median, geom = "point", shape = 21, size = 2, fill = "white", colour = "grey30", show.legend = FALSE) + scale_fill_manual(values = STANDARD_COLORS) + scale_x_continuous(labels = label_number(suffix = "k NOK", accuracy = 1)) + labs(x = "Pris/m² (1 000 NOK)", y = NULL, title = "Pris per m² per boligstandard", subtitle = "Hvit prikk = median; boks = IQR") + theme_minimal(base_size = 13) + theme(panel.grid.major.y = element_blank())}```---## Prisfordeling per Kategori```{r price-violin, fig.height=5.5, fig.width=10}violin_df <- classified |> filter(!is.na(price_m), price_m > 0.3, price_m < 30) |> mutate(category = factor(category, levels = rev(levels(cat_counts$category))))# Only draw violins for categories with enough dataenough <- violin_df |> count(category) |> filter(n >= 5) |> pull(category)ggplot(violin_df |> filter(category %in% enough), aes(x = price_m, y = category, fill = category)) + geom_violin(trim = TRUE, show.legend = FALSE, alpha = 0.72, linewidth = 0.25) + geom_boxplot(width = 0.10, outlier.shape = NA, show.legend = FALSE, colour = "grey30", fill = "white", alpha = 0.55) + stat_summary(fun = median, geom = "point", shape = 21, size = 2, fill = "white", colour = "grey30", show.legend = FALSE) + scale_fill_manual(values = CAT_COLORS) + scale_x_continuous(labels = label_number(suffix = " M NOK", accuracy = 1), limits = c(0, 30)) + labs(x = "Prisantydning", y = NULL, title = "Prisfordeling per kategori", subtitle = "Hvit prikk = median; boks = IQR") + theme_minimal(base_size = 13) + theme(panel.grid.major.y = element_blank())```---## Verdi for Pengene::: {.callout-tip appearance="simple"}**Hvordan defineres «verdi for pengene» her?**For hver annonse beregner vi en **verdi-score** basert på et vektet gjennomsnitt av tre referanser:$$\text{Referansepris/m}^2 = \frac{\text{Nabolagsmedian} + \text{Standardmedian} + \text{Kategorimedian}}{3}$$$$\text{Verdi-score} = \frac{\text{Referansepris/m}^2}{\text{Annonsepris/m}^2}$$En score på **1,0** betyr at annonsen er priset nøyaktig på referansen.En score på **1,30** betyr at du betaler **30 % mindre per m²** enn referansen — ekte verdi.Scorer **under 1,0** indikerer premiumprising.Byens medianpris/m² brukes som fallback der nabolag eller standard mangler data.:::```{r value-scatter, fig.height=11, fig.width=11}val_df <- classified |> filter(!is.na(value_score), !is.na(size_sqm), size_sqm > 10, size_sqm < 450, value_score > 0.3, value_score < 3.5, price_sqm > 10000)ggplot(val_df, aes(x = size_sqm, y = value_score)) + geom_hline(yintercept = 1, linetype = "dashed", colour = "grey60", linewidth = 0.7) + geom_point(aes(colour = category, size = price_m), alpha = 0.5) + scale_colour_manual(values = CAT_COLORS, guide = "none") + scale_size_continuous(name = "Pris (M NOK)", range = c(1.5, 5), labels = label_number(suffix = " M")) + scale_y_continuous(labels = label_number(accuracy = 0.1, suffix = "×")) + scale_x_continuous(labels = label_number(suffix = " m²")) + facet_wrap(~category, scales = "free", ncol = 3) + labs(x = "Størrelse (m²)", y = "Verdi-score", title = "Verdi for pengene vs størrelse per kategori", subtitle = "Stiplet linje = vektet referanse (score 1,0). Punktstørrelse = pris i M NOK.") + theme_minimal(base_size = 12) + theme(strip.text = element_text(face = "bold", size = 10)) + guides(size = guide_legend(override.aes = list(alpha = 0.7)))```### Topp 10 Beste Verdi-Annonser```{r value-table}top10 <- classified |> filter(!is.na(value_score), !is.na(price), !is.na(size_sqm), size_sqm >= 25, price_sqm > 10000) |> arrange(desc(value_score)) |> slice_head(n = 10) |> transmute( Annonse = ifelse(!is.na(url), paste0('<a href="', url, '" target="_blank">', str_trunc(coalesce(title, "—"), 40), '</a>'), coalesce(title, "—")), Pris = paste0(format(price, big.mark = " "), " NOK"), `Størrelse` = paste0(size_sqm, " m²"), `kr/m²` = paste0(format(round(price_sqm), big.mark = " "), " NOK"), Kategori = category, `Verdi-score` = paste0(round(value_score, 2), "× (+", round(value_pct), "%)") )datatable(top10, escape = FALSE, rownames = FALSE, options = list(dom = "t", pageLength = 10, scrollX = TRUE))```---## Pris per m² per Nabolag```{r psqm-hood, fig.height=5, fig.width=9}hood_df <- classified |> filter(!is.na(neighborhood), neighborhood != "", !is.na(price_sqm), price_sqm > 10000, price_sqm < 250000)hood_counts <- hood_df |> count(neighborhood) |> filter(n >= 3)if (nrow(hood_counts) < 3) { cat("> Ikke nok nabolagsdata ennå — vises etter hvert som flere annonser hentes og geokodes.\n")} else { hood_summary <- hood_df |> filter(neighborhood %in% hood_counts$neighborhood) |> group_by(neighborhood) |> summarise( med_psqm = median(price_sqm), n = n(), .groups = "drop" ) |> arrange(desc(med_psqm)) |> slice_head(n = 20) |> mutate(neighborhood = factor(neighborhood, levels = rev(neighborhood))) ggplot(hood_summary, aes(x = med_psqm / 1000, y = neighborhood)) + geom_col(fill = "#264653", alpha = 0.82, width = 0.7) + geom_text(aes(label = paste0(round(med_psqm / 1000), "k (n=", n, ")")), hjust = -0.1, size = 3.2, colour = "grey30") + scale_x_continuous( labels = label_number(suffix = "k NOK"), expand = expansion(mult = c(0, 0.18)) ) + labs(x = "Medianpris/m² (1 000 NOK)", y = NULL, title = "Medianpris per m² per nabolag", subtitle = "Topp 20 nabolag med ≥ 3 annonser") + theme_minimal(base_size = 13) + theme(panel.grid.major.y = element_blank())}```---## Pris per m² per Kategori Over Tid*Hvordan utvikler gjennomsnittlig prisantydning per m² seg per segment mellom hentekjøringer?*```{r psqm-timeseries, fig.height=11, fig.width=12}psqm_ts <- classified |> filter(!is.na(price_sqm), price_sqm > 10000, price_sqm < 250000, !is.na(scraped_date)) |> group_by(scraped_date, category) |> summarise( avg_psqm = mean(price_sqm, na.rm = TRUE), n = n(), .groups = "drop" ) |> filter(n >= 3)if (length(unique(psqm_ts$scraped_date)) < 2) { cat("> Tidsserien vises etter minst 2 hentekjøringer med klassifiserte annonser.\n")} else { ggplot(psqm_ts, aes(x = scraped_date, y = avg_psqm / 1000, colour = category)) + geom_line(linewidth = 0.8, alpha = 0.85) + geom_point(aes(size = n), alpha = 0.75) + scale_colour_manual(values = CAT_COLORS, guide = "none") + scale_size_continuous(name = "Annonser", range = c(2, 5)) + scale_x_date(date_labels = "%d %b", date_breaks = "2 weeks") + scale_y_continuous(labels = label_number(suffix = "k NOK", accuracy = 1)) + facet_wrap(~category, scales = "free_y", ncol = 3) + labs(x = NULL, y = "Gj.sn. pris/m² (1 000 NOK)", title = "Gjennomsnittlig pris per m² per kategori over tid", subtitle = "Punktstørrelse = antall annonser. Kategorier med < 3 annonser per kjøring skjult.") + theme_minimal(base_size = 12) + theme( strip.text = element_text(face = "bold", size = 10), axis.text.x = element_text(angle = 30, hjust = 1) ) + guides(size = guide_legend(override.aes = list(alpha = 0.7)))}```---## Daglig Annonseaktivitet```{r daily-activity, fig.height=3.5, fig.width=9}daily <- df |> count(scraped_date, name = "n") |> filter(!is.na(scraped_date)) |> arrange(scraped_date)if (nrow(daily) < 2) { cat("> Daglig trend vises etter minst 2 dager med henting.\n")} else { ggplot(daily, aes(x = scraped_date, y = n)) + geom_col(fill = "#2A9D8F", alpha = 0.85, width = 0.7) + geom_text(aes(label = n), vjust = -0.4, size = 3, colour = "grey35") + scale_x_date(date_labels = "%b %d") + scale_y_continuous(expand = expansion(mult = c(0, 0.15))) + labs(x = NULL, y = "Nye annonser", title = "Nye annonser hentet per dag", subtitle = "Unike annonser lagt til databasen per kjøring") + theme_minimal(base_size = 13) + theme(panel.grid.major.x = element_blank())}```---## Hva Driver Boligprisene i Oslo?::: {.callout-note appearance="simple"}En OLS-regresjon av **log(pris)** på alle tilgjengelige prediktorer. Koeffisientene viser **% prisforskjell** knyttet til hver faktor, med andre holdt konstant. Referansenivåer: *Central urban* (boligkategori), *Good standard* (boligstandard). Standard inkluderes når ≥ 30 % av annonsene er klassifisert. Feilstenger = 95 % KI; grått = ikke signifikant.:::```{r price-drivers, fig.height=9, fig.width=10}reg_df <- classified |> filter(!is.na(price), !is.na(size_sqm), price > 500000, price < 50e6, size_sqm > 10, size_sqm < 450) |> mutate( log_price = log(price), size_std = as.numeric(scale(size_sqm)), rooms_std = if_else(!is.na(rooms), as.numeric(scale(rooms)), NA_real_), year_std = if_else(!is.na(year_built), as.numeric(scale(year_built)), NA_real_), floor_std = if_else(!is.na(floor), as.numeric(scale(floor)), NA_real_), has_balcony_i = if_else(!is.na(has_balcony), as.numeric(has_balcony), NA_real_), category = factor(category), std_factor = factor( if_else(!is.na(standard) & standard != "", standard, NA_character_), levels = STANDARD_ORDER ) )if (nrow(reg_df) < 30) { cat("> Ikke nok data ennå — trenger minst 30 klassifiserte annonser med pris og størrelse.\n")} else { # Reference levels ref_cat <- if ("Central urban" %in% levels(reg_df$category)) "Central urban" else levels(reg_df$category)[1] reg_df$category <- relevel(reg_df$category, ref = ref_cat) reg_df$std_factor <- relevel(reg_df$std_factor, ref = "Good standard") # Include each predictor only when ≥ 30% of rows have non-NA values preds <- "size_std" if (sum(!is.na(reg_df$rooms)) > nrow(reg_df) * 0.3) preds <- c(preds, "rooms_std") if (sum(!is.na(reg_df$year_built)) > nrow(reg_df) * 0.3) preds <- c(preds, "year_std") if (sum(!is.na(reg_df$floor_std)) > nrow(reg_df) * 0.3) preds <- c(preds, "floor_std") if (sum(!is.na(reg_df$has_balcony_i)) > nrow(reg_df) * 0.3) preds <- c(preds, "has_balcony_i") preds <- c(preds, "category") if (sum(!is.na(reg_df$std_factor)) > nrow(reg_df) * 0.3) preds <- c(preds, "std_factor") fit <- lm(as.formula(paste("log_price ~", paste(preds, collapse = " + "))), data = reg_df, na.action = na.omit) s <- summary(fit) r2 <- round(s$r.squared * 100, 1) n_obs <- nrow(model.frame(fit)) coef_mat <- s$coefficients coef_df <- data.frame( term = rownames(coef_mat), estimate = coef_mat[, "Estimate"], se = coef_mat[, "Std. Error"], stringsAsFactors = FALSE ) |> filter(term != "(Intercept)") |> mutate( lower = estimate - 1.96 * se, upper = estimate + 1.96 * se, sig = sign(lower) == sign(upper), pct = (exp(estimate) - 1) * 100, pct_lo = (exp(lower) - 1) * 100, pct_hi = (exp(upper) - 1) * 100, # Assign facet group BEFORE stripping prefix predictor_type = case_when( term %in% c("size_std", "rooms_std", "year_std", "floor_std", "has_balcony_i") ~ "Kontinuerlige prediktorer", startsWith(term, "category") ~ paste0("Boligkategori (vs ", ref_cat, ")"), startsWith(term, "std_factor") ~ "Boligstandard (vs Good standard)", TRUE ~ "Annet" ), # Clean up term labels term = gsub("^(category|std_factor)", "", term), term = case_when( term == "size_std" ~ "Størrelse (per SD)", term == "rooms_std" ~ "Rom (per SD)", term == "year_std" ~ "Byggeår (per SD)", term == "floor_std" ~ "Etasje (per SD)", term == "has_balcony_i" ~ "Balkong (ja vs nei)", TRUE ~ term ) ) pct_label <- function(x) paste0(ifelse(x >= 0, "+", ""), round(x), "%") ggplot(coef_df, aes(x = pct, y = reorder(term, pct), colour = sig)) + geom_vline(xintercept = 0, linetype = "dashed", colour = "grey55", linewidth = 0.7) + geom_errorbarh(aes(xmin = pct_lo, xmax = pct_hi), height = 0.35, linewidth = 0.55, colour = "grey65") + geom_point(size = 3.2) + geom_text(aes(label = pct_label(pct)), hjust = -0.35, size = 3, show.legend = FALSE) + scale_colour_manual( values = c("TRUE" = "#1a1a2e", "FALSE" = "#bbbbbb"), labels = c("TRUE" = "Signifikant (95 % KI)", "FALSE" = "Ikke signifikant"), name = NULL ) + scale_x_continuous( labels = pct_label, expand = expansion(mult = c(0.05, 0.20)) ) + facet_grid(rows = vars(predictor_type), scales = "free_y", space = "free_y") + labs( x = "Sammenheng med prisantydning (% forskjell)", y = NULL, title = "Hva driver boligprisene i Oslo?", subtitle = paste0( "OLS på log(pris), n = ", format(n_obs, big.mark = " "), " annonser. R² = ", r2, "%." ) ) + theme_minimal(base_size = 13) + theme( strip.text = element_text(face = "bold", size = 11), panel.grid.major.y = element_blank(), legend.position = "bottom" )}```---## Meglerprising: Over eller Under Lokalt Markedsnivå?::: {.callout-note appearance="simple"}Hvert panel viser én boligstandard. For hvert panel sammenlignes meglernes gjennomsnittlige prisantydning/m² mot nabolagsmedianen (faller tilbake til bymedian der færre enn 3 annonser finnes i et nabolag). Kun megler–standard-kombinasjoner med ≥ 3 annonser vises. Meglere er sortert etter samlet gjennomsnittsavvik på tvers av alle standardnivåer.:::```{r broker-pricing, fig.height=10, fig.width=12}# Neighbourhood reference: median price/m² where ≥ 3 listings existhood_ref <- df |> filter(!is.na(neighborhood), neighborhood != "", !is.na(price_sqm), price_sqm > 10000, price_sqm < 250000) |> group_by(neighborhood) |> summarise(hood_med = median(price_sqm), n_hood = n(), .groups = "drop") |> filter(n_hood >= 3)city_med <- median(df$price_sqm[df$price_sqm > 10000 & df$price_sqm < 250000], na.rm = TRUE)broker_listings <- df |> filter(!is.na(broker), broker != "", !is.na(price_sqm), price_sqm > 10000, price_sqm < 250000) |> left_join(hood_ref, by = "neighborhood") |> mutate( ref_psqm = if_else(!is.na(hood_med), hood_med, city_med), delta = (price_sqm - ref_psqm) / ref_psqm * 100 )broker_std_listings <- broker_listings |> filter(!is.na(standard), standard != "") |> mutate(standard = factor(standard, levels = STANDARD_ORDER))broker_overall_order <- broker_std_listings |> group_by(broker) |> summarise(overall_delta = mean(delta, na.rm = TRUE), .groups = "drop") |> arrange(overall_delta) |> pull(broker)broker_std_summary <- broker_std_listings |> group_by(broker, standard) |> summarise( mean_delta = mean(delta, na.rm = TRUE), se = sd(delta, na.rm = TRUE) / sqrt(n()), n = n(), .groups = "drop" ) |> filter(n >= 3) |> mutate(broker = factor(broker, levels = broker_overall_order))if (nrow(broker_std_summary) < 2) { cat("> Ikke nok meglerdata med standardklassifisering ennå.\n")} else { pct_lbl <- function(x) paste0(ifelse(x >= 0, "+", ""), round(x, 1), "%") ggplot(broker_std_summary, aes(x = mean_delta, y = broker)) + geom_vline(xintercept = 0, linetype = "dashed", colour = "grey55", linewidth = 0.7) + geom_errorbarh( aes(xmin = mean_delta - 1.96 * se, xmax = mean_delta + 1.96 * se), height = 0.35, linewidth = 0.55, colour = "grey65" ) + geom_point(aes(colour = mean_delta > 0, size = n)) + geom_text( aes(label = paste0(pct_lbl(mean_delta), " (n=", n, ")")), hjust = -0.15, size = 2.8, colour = "grey30" ) + scale_colour_manual( values = c("TRUE" = "#C0392B", "FALSE" = "#2A9D8F"), labels = c("TRUE" = "Over områdemedian", "FALSE" = "Under områdemedian"), name = NULL ) + scale_size_continuous(name = "Annonser", range = c(2, 5)) + scale_x_continuous( labels = pct_lbl, expand = expansion(mult = c(0.05, 0.30)) ) + facet_wrap(~standard, scales = "free_y", ncol = 2) + labs( x = "Gj.sn. pris/m² vs nabolagsmedian (%)", y = NULL, title = "Lister meglere over eller under lokalt markedsnivå — per boligstandard?", subtitle = "Rød = over, teal = under nabolagsmedian. Feilstenger = 95 % KI. Kun kombinasjoner med ≥ 3 annonser." ) + theme_minimal(base_size = 12) + theme( strip.text = element_text(face = "bold", size = 10), panel.grid.major.y = element_blank(), legend.position = "bottom" ) + guides(colour = guide_legend(override.aes = list(size = 3)))}```---## Megler: Verdi for Pengene*Hvilket gjennomsnittlig verdi-score har annonsene til hver megler? Positiv score betyr at meglernes annonser typisk er billigere enn den vektede referansen (nabolag + standard + kategori) — negativ betyr at de typisk er dyrere.*```{r broker-value, fig.height=5.5, fig.width=10}broker_value <- classified |> filter(!is.na(broker), broker != "", !is.na(value_pct), price_sqm > 35000) |> group_by(broker) |> summarise( mean_vpct = mean(value_pct, na.rm = TRUE), se = sd(value_pct, na.rm = TRUE) / sqrt(n()), n = n(), .groups = "drop" ) |> filter(n >= 3) |> arrange(mean_vpct)if (nrow(broker_value) < 2) { cat("> Ikke nok meglerdata ennå.\n")} else { pct_lbl <- function(x) paste0(ifelse(x >= 0, "+", ""), round(x, 1), "%") ggplot(broker_value, aes(x = mean_vpct, y = reorder(broker, mean_vpct))) + geom_vline(xintercept = 0, linetype = "dashed", colour = "grey55", linewidth = 0.7) + geom_errorbarh( aes(xmin = mean_vpct - 1.96 * se, xmax = mean_vpct + 1.96 * se), height = 0.35, linewidth = 0.55, colour = "grey65" ) + geom_point(aes(colour = mean_vpct > 0, size = n)) + geom_text( aes(label = paste0(pct_lbl(mean_vpct), " (n=", n, ")")), hjust = -0.15, size = 3, colour = "grey30" ) + scale_colour_manual( values = c("TRUE" = "#2A9D8F", "FALSE" = "#C0392B"), labels = c("TRUE" = "Under referanse (god verdi)", "FALSE" = "Over referanse (dyr)"), name = NULL ) + scale_size_continuous(name = "Annonser", range = c(2.5, 6)) + scale_x_continuous( labels = pct_lbl, expand = expansion(mult = c(0.05, 0.25)) ) + labs( x = "Gj.sn. verdi-score (% vs vektet referanse)", y = NULL, title = "Megler: gjennomsnittlig verdi for pengene", subtitle = paste0( "Positiv = annonsene er billigere enn referansen (nabolag + standard + kategori). ", "Feilstenger = 95 % KI. Kun meglere med ≥ 3 annonser." ) ) + theme_minimal(base_size = 13) + theme( panel.grid.major.y = element_blank(), legend.position = "bottom" ) + guides(colour = guide_legend(override.aes = list(size = 3)))}```---## Ukens Bolig```{r pick-of-week}# Algorithm:# 1. Filter to classified listings with full data (price, size, address, url)# 2. Require size >= 30 m², valid value_score, scraped within 14 days# (fall back to all-time if too few recent listings)# 3. Rank by value_score (higher = cheaper per m² vs weighted reference), break ties by size# 4. Pick #1pick_pool <- classified |> filter(!is.na(price), !is.na(size_sqm), !is.na(url), !is.na(value_score), price_sqm > 35000, # excludes renovation/distressed properties size_sqm >= 30, category != "Unclassified", category != "Renovation", coalesce(standard, "") != "Renovation project") |> arrange(desc(value_score), desc(size_sqm))# Prefer recent listingsrecent_pool <- pick_pool |> filter(scraped_date >= Sys.Date() - 14)if (nrow(recent_pool) >= 1) pick_pool <- recent_poolpick <- pick_pool |> slice_head(n = 1)if (nrow(pick) == 0) { cat("> Ikke nok klassifiserte annonser til å gi en anbefaling ennå.\n")} else { # Build the "why chosen" explanation why_text <- paste0( "Valgt blant ", nrow(pick_pool), " kandidat", if (nrow(pick_pool) != 1) "er" else "", " som beste verdi for pengene i sitt segment. ", "Med ", format(round(pick$price_sqm), big.mark = "\u00a0"), "\u00a0NOK/m\u00b2 er den ", abs(round(pick$value_pct)), "\u00a0% ", if (pick$value_pct >= 0) "under" else "over", " den vektede referansen", if (!is.na(pick$ref_psqm)) paste0(" (", format(round(pick$ref_psqm), big.mark = "\u00a0"), "\u00a0NOK/m\u00b2)") else "", ". Referansen er gjennomsnittet av nabolagsmedian, standardmedian og kategorimedian for denne boligen." ) cat(htmltools::doRenderTags( htmltools::tags$div( class = "card border-success mb-4", style = "max-width:680px; border-width:2px;", htmltools::tags$div( class = "card-header bg-success text-white", htmltools::tags$strong("Ukens Bolig") ), htmltools::tags$div( class = "card-body", htmltools::tags$h5( class = "card-title mb-1", htmltools::tags$a( href = pick$url, target = "_blank", rel = "noopener", if (!is.na(pick$title) && nchar(trimws(pick$title)) > 0) pick$title else "Vis annonse" ) ), htmltools::tags$p( class = "text-muted mb-2", style = "font-size:0.9em", if (!is.na(pick$address) && nchar(trimws(pick$address)) > 0) pick$address else "Oslo" ), htmltools::tags$div( class = "d-flex flex-wrap gap-3 mb-3", htmltools::tags$div( htmltools::tags$div(class = "text-muted", style = "font-size:0.75em", "PRIS"), htmltools::tags$strong( if (!is.na(pick$price)) paste0(format(pick$price, big.mark = " "), " NOK") else "—" ) ), htmltools::tags$div( htmltools::tags$div(class = "text-muted", style = "font-size:0.75em", "STØRRELSE"), htmltools::tags$strong( if (!is.na(pick$size_sqm)) paste0(pick$size_sqm, " m²") else "—" ) ), htmltools::tags$div( htmltools::tags$div(class = "text-muted", style = "font-size:0.75em", "ROM"), htmltools::tags$strong( if (!is.na(pick$rooms)) as.character(pick$rooms) else "—" ) ), htmltools::tags$div( htmltools::tags$div(class = "text-muted", style = "font-size:0.75em", "PRIS / m²"), htmltools::tags$strong( if (!is.na(pick$price_sqm)) paste0(format(round(pick$price_sqm), big.mark = " "), " NOK") else "—" ) ) ), # Category badge + value badge htmltools::tags$p( htmltools::tags$span( class = "badge rounded-pill text-white me-2", style = paste0("background-color:", CAT_COLORS[pick$category]), pick$category ), if (!is.na(pick$value_score)) htmltools::tags$span( class = if (pick$value_pct >= 0) "badge bg-success-subtle text-success-emphasis" else "badge bg-warning-subtle text-warning-emphasis", paste0(ifelse(pick$value_pct >= 0, "+", ""), round(pick$value_pct), "% vs vektet referanse") ) ), # Why chosen htmltools::tags$p( class = "card-text mb-2", style = "font-size:0.88em; border-left:3px solid #198754; padding-left:8px; color:#155724", htmltools::tags$strong("Hvorfor valgt: "), why_text ), # AI category reasoning if (!is.na(pick$category_reasoning) && nchar(pick$category_reasoning) > 5) htmltools::tags$p( class = "card-text fst-italic text-muted", style = "font-size:0.88em; border-left:3px solid #ccc; padding-left:8px", paste0("\u201C", pick$category_reasoning, "\u201D") ), htmltools::tags$a( href = pick$url, target = "_blank", rel = "noopener", class = "btn btn-outline-success btn-sm", "Se på finn.no \u2192" ) ), htmltools::tags$div( class = "card-footer text-muted", style = "font-size:0.8em", paste0("Valgt av verdi-score algoritme · Hentet ", format(pick$scraped_date, "%d %b %Y")) ) ) ))}```---*Data hentet fra [finn.no](https://www.finn.no/realestate/homes/search.html?location=0.20061){target="_blank"} kun til personlig/utdanningsformål.Kategorier og verdi-scorer beregnet av Claude AI. Dette er ikke finansiell eller investeringsrådgivning.*